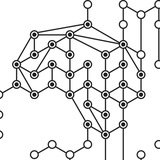
Всем привет! Продолжаем рассказывать про интересные #paper
Новый вид сверточного слоя
Мы давно привыкли к тому, как работает сверточный слой в нейронной сети: фильтр "скользит" по картинке и его элементы умножаются на соответствующие элементы изображения. Таким образом сверточный слой "реагирует" на определенные паттерны, которые есть на изображении. Эта идея свертки пришла из биологии: свёрточные слои задумывались как подобие особых нейронов в мозге человека, которые также реагируют на определенные паттерны картинки.
Но что если привычное нам устройство свертки — не единственно возможное? Авторы статьи AdderNet: Do We Really Need Multiplications in Deep Learning? предложили альтернативное устройство сверточных слоев. И сеть ResNet с этими слоями показывает лучшие результаты на задаче классификации CIFAR, чем обычные CNN!
В чем особенность свертки в AdderNet:
Когда мы сворачиваем картинку с помощью фильтра, результат свертки одного кусочка картинки говорит о том, насколько этот кусочек похож на фильтр. В AdderNet предложили иной способ оценивания "похожести" фрагмента картинки и фильтра, чем это было в обычных CNN.
Идея очень простая: сравнивать фрагмент картинки и фильтр с помощью l1-расстояния. То есть, на каждом шаге свертки вместо умножения элементов картинки на фильтр мы будем считать l1-расстояние между элементами фильтра и элементами картинки. Это позволит избежать операции умножения в сверточных слоях, что сильно ускорит вычисление сверток. Авторы назвали предложенный сверточный слоем слоем Adder.
Однако есть проблема: В таком виде — просто заменив свертку на l1 расстояние — сеть будет работать плохо. Дело в том, что l1-расстояние — линейная неотрицательная функция, т.е. на выходе слоя Adder в карте активации будут только неотрицательные значения. И если использовать свертки Adder с функцией активации ReLU, то получившаяся модель будет композицией линейных функций и сможет аппроксимировать только линейные зависимости.
Для решения этой проблемы авторы предлагают использовать слой Adder вместе с batchnorm. Блогодаря batchnorm значения на выходе слоя снова могут стать отрицательными. А значит, модель сможет выучить нелинейные зависимости.
Есть и вторая проблема: обучение слоя Adder. Чтобы обучить AdderNet с помощью градиентного спуска, нужно считать градиент для l1. Производная модуля принимает всего два значения — ±1. Из-за этого значения градиента получаются очень разреженными, и с помощью них очень тяжело получить оптимальные значения параметров (*Sgn grad* на первой картинке).
Однако и эту проблему авторам статьи удалось побороть. Они предложили вместо реального градиента для l1 использовать обычную разность между фильтром и фрагментом изображения. Также предлагается обрезать слишком большие по модулю значения этого псевдоградиента для избежания взрыва градиентов(*Fp grad* на первой картинке).
Тут обнаружился еще один нюанс: описанные выше градиенты получаются сильно меньше, чем у обычной CNN (см. *ILR* на первой картинке). Поэтому для AdderNet используется адаптивный learning rate, который обратно пропорционален норме градиента (см. *ALR* на первой картинке).
В итоге такой подход оправдывает себя. AdderNet работает быстрее и лучше обычной CNN с такой же архитектурой. У такой сверточной сети есть еще один плюс: фичи, выдаваемые такой сетью, основываются на расстоянии, а не на угле. Это значит, что кластеры из классов лучше разделены между собой, в отличии от обычной сети, где все кластеры сливаются в одну точку около нуля.
Ссылка на статью тут.
Новый вид сверточного слоя
Мы давно привыкли к тому, как работает сверточный слой в нейронной сети: фильтр "скользит" по картинке и его элементы умножаются на соответствующие элементы изображения. Таким образом сверточный слой "реагирует" на определенные паттерны, которые есть на изображении. Эта идея свертки пришла из биологии: свёрточные слои задумывались как подобие особых нейронов в мозге человека, которые также реагируют на определенные паттерны картинки.
Но что если привычное нам устройство свертки — не единственно возможное? Авторы статьи AdderNet: Do We Really Need Multiplications in Deep Learning? предложили альтернативное устройство сверточных слоев. И сеть ResNet с этими слоями показывает лучшие результаты на задаче классификации CIFAR, чем обычные CNN!
В чем особенность свертки в AdderNet:
Когда мы сворачиваем картинку с помощью фильтра, результат свертки одного кусочка картинки говорит о том, насколько этот кусочек похож на фильтр. В AdderNet предложили иной способ оценивания "похожести" фрагмента картинки и фильтра, чем это было в обычных CNN.
Идея очень простая: сравнивать фрагмент картинки и фильтр с помощью l1-расстояния. То есть, на каждом шаге свертки вместо умножения элементов картинки на фильтр мы будем считать l1-расстояние между элементами фильтра и элементами картинки. Это позволит избежать операции умножения в сверточных слоях, что сильно ускорит вычисление сверток. Авторы назвали предложенный сверточный слоем слоем Adder.
Однако есть проблема: В таком виде — просто заменив свертку на l1 расстояние — сеть будет работать плохо. Дело в том, что l1-расстояние — линейная неотрицательная функция, т.е. на выходе слоя Adder в карте активации будут только неотрицательные значения. И если использовать свертки Adder с функцией активации ReLU, то получившаяся модель будет композицией линейных функций и сможет аппроксимировать только линейные зависимости.
Для решения этой проблемы авторы предлагают использовать слой Adder вместе с batchnorm. Блогодаря batchnorm значения на выходе слоя снова могут стать отрицательными. А значит, модель сможет выучить нелинейные зависимости.
Есть и вторая проблема: обучение слоя Adder. Чтобы обучить AdderNet с помощью градиентного спуска, нужно считать градиент для l1. Производная модуля принимает всего два значения — ±1. Из-за этого значения градиента получаются очень разреженными, и с помощью них очень тяжело получить оптимальные значения параметров (*Sgn grad* на первой картинке).
Однако и эту проблему авторам статьи удалось побороть. Они предложили вместо реального градиента для l1 использовать обычную разность между фильтром и фрагментом изображения. Также предлагается обрезать слишком большие по модулю значения этого псевдоградиента для избежания взрыва градиентов(*Fp grad* на первой картинке).
Тут обнаружился еще один нюанс: описанные выше градиенты получаются сильно меньше, чем у обычной CNN (см. *ILR* на первой картинке). Поэтому для AdderNet используется адаптивный learning rate, который обратно пропорционален норме градиента (см. *ALR* на первой картинке).
В итоге такой подход оправдывает себя. AdderNet работает быстрее и лучше обычной CNN с такой же архитектурой. У такой сверточной сети есть еще один плюс: фичи, выдаваемые такой сетью, основываются на расстоянии, а не на угле. Это значит, что кластеры из классов лучше разделены между собой, в отличии от обычной сети, где все кластеры сливаются в одну точку около нуля.
Ссылка на статью тут.
Odeuropa: музей запахов
#tech
Мы — люди — воспринимаем мир с помощью органов чувств. С течением столетий мир меняется, и меняется наше его восприятие: меняются ландшафты, облики городов, привычные нам звуки и запахи. Если в средние века в городе часто были слышны звуки колесниц и запах керосина, то сейчас город — это рев машин на шоссе и запах бензина.
Когда мы изучаем историю, мы изучаем ее по книгам, музеям и кино. Мы можем "услышать", "увидеть" и "потрогать" прошлое. Но не можем "услышать его запах". И это — большое упущение в нашей попытке окунуться в прошлое и действительно понять, как тогда была устроена жизнь.
Ученые из Европейского Союза решили восполнить этот пробел. Для этого они создали проект Odeuropa. Цель проекта — собрать данные о том, какие запахи преобладали в разное время в разных местах Европы, как к ним относились разные культуры и какие события ассоциировались у людей с определенными запахами.
Для реализации задумки будет использоваться искусственный интеллект. Нейронные сети для работы с текстами и изображениями будут просматривать средневековые книги и картины и выделять оттуда всю информацию, которая связана с запахами. Далее выделенную информацию проанализируют и соберут ее в граф знаний (базу знаний)
Проект поможет музеям повысить погружение посетителей в дух времени, "почувствовать" прошлое всеми органами чувств. Также это будет частью Европейского наследия — поможет лучше сохранить и передать потомкам культуру времен и разных народов Европы.
Как вам идея проекта? Запах какого времени и места вам интересно было бы ощутить?)
#tech
Мы — люди — воспринимаем мир с помощью органов чувств. С течением столетий мир меняется, и меняется наше его восприятие: меняются ландшафты, облики городов, привычные нам звуки и запахи. Если в средние века в городе часто были слышны звуки колесниц и запах керосина, то сейчас город — это рев машин на шоссе и запах бензина.
Когда мы изучаем историю, мы изучаем ее по книгам, музеям и кино. Мы можем "услышать", "увидеть" и "потрогать" прошлое. Но не можем "услышать его запах". И это — большое упущение в нашей попытке окунуться в прошлое и действительно понять, как тогда была устроена жизнь.
Ученые из Европейского Союза решили восполнить этот пробел. Для этого они создали проект Odeuropa. Цель проекта — собрать данные о том, какие запахи преобладали в разное время в разных местах Европы, как к ним относились разные культуры и какие события ассоциировались у людей с определенными запахами.
Для реализации задумки будет использоваться искусственный интеллект. Нейронные сети для работы с текстами и изображениями будут просматривать средневековые книги и картины и выделять оттуда всю информацию, которая связана с запахами. Далее выделенную информацию проанализируют и соберут ее в граф знаний (базу знаний)
Проект поможет музеям повысить погружение посетителей в дух времени, "почувствовать" прошлое всеми органами чувств. Также это будет частью Европейского наследия — поможет лучше сохранить и передать потомкам культуру времен и разных народов Европы.
Как вам идея проекта? Запах какого времени и места вам интересно было бы ощутить?)
Odeuropa
Smell Heritage – Sensory Mining - Odeuropa
What role do smells play in European culture? How can museums and archives enhance their impact through olfactory storytelling? How can we find, document and represent smells from the past? The Odeuropa project develops novel methods to collect information…
Сегодня мы предлагаем вам послушать выпуск подкаста Запуск завтра:
Как с помощью искусственного интеллекта выращивают марихуану и лечат рак.
#podcast
Гостья подкаста — сооснователь и гендиректор стартапа Fermata Валерия Коган.
Fermata — стартап в сфере агротехнологий. Он предоставляет решения на основе ИИ, которые следят за состоянием растений в режиме реального времени. Это помогает прогнозировать урожай, выявлять заболевания растений и оптимизировать издержки бизнеса.
За 2019 и 2020 года стартап привлек 5млн инвестиций, а Валерия Коган стала номинантом рейтинга Forbes "самые перспективные россияне моложе 30 лет."
Валерия — выпускница МФТИ. Во время учебы на Физтехе она начала заниматься машинным обучением в биологии, и далее продолжила исследования в этой области в аспирантуре в Израиле. Осенью 2018 года от знакомых она узнала, с какими проблемами сталкивается агробизнес в России, и это побудило ее создать стартап.
В выпуске подкаста его ведущий Самат поговорил с Валерией о том, как искусственный интеллект меняет выращивание овощей, почему с марихуаной легче работать, чем с помидорами, как собрать датасет больных растений и как Лера использует одну и ту же технологию в сельском хозяйстве и в онкологии.
Также рекомендуем и другие выпуски подкаста "Запуск завтра". Это подкасты о технологиях на любой вкус: про биткоин, блокчеин, цифровое искусство, VR и о том, как устроиться на работу в Google и Amazon =)
#подкаст
Как с помощью искусственного интеллекта выращивают марихуану и лечат рак.
#podcast
Гостья подкаста — сооснователь и гендиректор стартапа Fermata Валерия Коган.
Fermata — стартап в сфере агротехнологий. Он предоставляет решения на основе ИИ, которые следят за состоянием растений в режиме реального времени. Это помогает прогнозировать урожай, выявлять заболевания растений и оптимизировать издержки бизнеса.
За 2019 и 2020 года стартап привлек 5млн инвестиций, а Валерия Коган стала номинантом рейтинга Forbes "самые перспективные россияне моложе 30 лет."
Валерия — выпускница МФТИ. Во время учебы на Физтехе она начала заниматься машинным обучением в биологии, и далее продолжила исследования в этой области в аспирантуре в Израиле. Осенью 2018 года от знакомых она узнала, с какими проблемами сталкивается агробизнес в России, и это побудило ее создать стартап.
В выпуске подкаста его ведущий Самат поговорил с Валерией о том, как искусственный интеллект меняет выращивание овощей, почему с марихуаной легче работать, чем с помидорами, как собрать датасет больных растений и как Лера использует одну и ту же технологию в сельском хозяйстве и в онкологии.
Также рекомендуем и другие выпуски подкаста "Запуск завтра". Это подкасты о технологиях на любой вкус: про биткоин, блокчеин, цифровое искусство, VR и о том, как устроиться на работу в Google и Amazon =)
#подкаст
This media is not supported in your browser
VIEW IN TELEGRAM
Добавьте глубины вашим фото
#tech
Google Photos представили новую технологию: добавление глубины 2d-фотографиям.
Только посмотрите на гифку к посту! Вот так "оживить" можно любое фото, снятое самой обычной камерой. Даже то, которое сняли в 2007 году на "мыльницу" или кнопочный Samsung.
Как работает технология:
Для получения 3d-изображения из 2d нужна его карта глубины. Обычно карту глубины получают так: фотографируют предмет с нескольких камер, находящихся на фиксированном расстоянии друг от друга, и сопоставляют точки на этих фотографиях. Поэтому в современных моделях мобильных телефонов чаще всего встроены по две, а то и три камеры.
Google же применила ИИ для построения карты глубины фотографии. Обученная ими сверточная нейросеть способна строить карту глубины на основе единственного 2d-фото.
Технология уже работает в Google Photos: ИИ "оживляет" ваши памятные фотографии, чтобы вы глубже смогли окунуться в момент, который запечатлели на снимке.
Более подробно о технологии читайте в блоге Google AI
#tech
Google Photos представили новую технологию: добавление глубины 2d-фотографиям.
Только посмотрите на гифку к посту! Вот так "оживить" можно любое фото, снятое самой обычной камерой. Даже то, которое сняли в 2007 году на "мыльницу" или кнопочный Samsung.
Как работает технология:
Для получения 3d-изображения из 2d нужна его карта глубины. Обычно карту глубины получают так: фотографируют предмет с нескольких камер, находящихся на фиксированном расстоянии друг от друга, и сопоставляют точки на этих фотографиях. Поэтому в современных моделях мобильных телефонов чаще всего встроены по две, а то и три камеры.
Google же применила ИИ для построения карты глубины фотографии. Обученная ими сверточная нейросеть способна строить карту глубины на основе единственного 2d-фото.
Технология уже работает в Google Photos: ИИ "оживляет" ваши памятные фотографии, чтобы вы глубже смогли окунуться в момент, который запечатлели на снимке.
Более подробно о технологии читайте в блоге Google AI
Помните AlphaFold? Это нейросеть, которая научилась определять структуру белка по последовательности аминокислот. Если пропустили — обязательно почитайте: это очень-очень важный прорыв для ИИ и биологии.
#paper #tech
Но в этом посте мы расскажем вам о другой нейросети в биологии: нейросети, которая предсказывает опасные мутации вирусов.
В чем состоит задача:
Многие болезни человечества вызваны вирусами. Против таких болезней разрабатывают вакцины. Вакцины помогают организму человека понять, как бороться с вирусом: как не дать ему проникнуть в клетки. Но есть сложность: вирусы способны мутировать. Некоторые мутации позволяют вирусам учиться избегать атаки имунной системы и сильнее проникать в клетки организма. При таких мутациях вакцины перестают действовать.
Пример: вирус COVID-19. Вы наверняка слышали о том, что в Англии и Южной Африке обнаружили мутации вируса, против которых существующие вакцины оказываются менее эффективны. По той же причине мутаций нужно делать прививку от гриппа каждый год: каждый год вирус гриппа сильно мутирует и против него нужны новые вакцины.
Отсюда возникает задача: по структуре вируса предсказывать, какие опасные мутации вируса могут возникнуть в ближайшее время.
Что обнаружили ученые:
Оказывается, биология имеет много общего с естественным языком: структура вируса очень похожа на структуру предложения.
Другими словами, иммунная система "считывает" вирус точно так же, как человек читает предложение на естественном языке.
Ученые выяснили это, обучив нейронную сеть для построения языковых моделей на мутациях вирусов. Оказалось, что сеть может успешно предсказывать мутации вирусов, которые приведут к защите вируса от иммунной системы.
У вируса, как и у предложения, есть два понятия: грамматическая корректность и смысл.
"Заразность" вируса соответствует грамматической структуре предложения: чем вирус более "грамматически правилен", тем он заразнее. Мутации же вируса соответствуют "смыслу" предложений. Те мутации, которые позволяют вирусу отражать атаки антител организма, сильно меняют "смысл" вируса.
Пример: рассмотрим предложение "Маше подарили красивую куклу". Изменим одно слово в предложении двумя способами: "Маше подарили милую куклу" и "Маше подарили ужасную куклу". Одно изменение (ужасную) меняет смысл предложения сильнее, чем другое (милую). Точно так же одни мутации изменяют вирус значительнее, чем другие.
Ученые обучили NLP модели на разных типах вирусаа ВИЧ (HIV). Точность модели составила от 0.69 до 0.85 — сильно больше случайного гадания.
Что это нам дает?
Умение предсказывать опасные мутации вирусов может помочь больницам оценивать ситуацию по заболеваниям в будущем. Например, информация о том, насколько серьезно вирус гриппа мутирует в следующем году, может помочь понять, насколько антитела людей, выработанные в этом году, помогут им в борьбе с гриппом через год.
Статью с более подробным разбором нейросети читайте тут. Также у ученых вышла статья в журнале Science.
#paper #tech
Но в этом посте мы расскажем вам о другой нейросети в биологии: нейросети, которая предсказывает опасные мутации вирусов.
В чем состоит задача:
Многие болезни человечества вызваны вирусами. Против таких болезней разрабатывают вакцины. Вакцины помогают организму человека понять, как бороться с вирусом: как не дать ему проникнуть в клетки. Но есть сложность: вирусы способны мутировать. Некоторые мутации позволяют вирусам учиться избегать атаки имунной системы и сильнее проникать в клетки организма. При таких мутациях вакцины перестают действовать.
Пример: вирус COVID-19. Вы наверняка слышали о том, что в Англии и Южной Африке обнаружили мутации вируса, против которых существующие вакцины оказываются менее эффективны. По той же причине мутаций нужно делать прививку от гриппа каждый год: каждый год вирус гриппа сильно мутирует и против него нужны новые вакцины.
Отсюда возникает задача: по структуре вируса предсказывать, какие опасные мутации вируса могут возникнуть в ближайшее время.
Что обнаружили ученые:
Оказывается, биология имеет много общего с естественным языком: структура вируса очень похожа на структуру предложения.
Другими словами, иммунная система "считывает" вирус точно так же, как человек читает предложение на естественном языке.
Ученые выяснили это, обучив нейронную сеть для построения языковых моделей на мутациях вирусов. Оказалось, что сеть может успешно предсказывать мутации вирусов, которые приведут к защите вируса от иммунной системы.
У вируса, как и у предложения, есть два понятия: грамматическая корректность и смысл.
"Заразность" вируса соответствует грамматической структуре предложения: чем вирус более "грамматически правилен", тем он заразнее. Мутации же вируса соответствуют "смыслу" предложений. Те мутации, которые позволяют вирусу отражать атаки антител организма, сильно меняют "смысл" вируса.
Пример: рассмотрим предложение "Маше подарили красивую куклу". Изменим одно слово в предложении двумя способами: "Маше подарили милую куклу" и "Маше подарили ужасную куклу". Одно изменение (ужасную) меняет смысл предложения сильнее, чем другое (милую). Точно так же одни мутации изменяют вирус значительнее, чем другие.
Ученые обучили NLP модели на разных типах вирусаа ВИЧ (HIV). Точность модели составила от 0.69 до 0.85 — сильно больше случайного гадания.
Что это нам дает?
Умение предсказывать опасные мутации вирусов может помочь больницам оценивать ситуацию по заболеваниям в будущем. Например, информация о том, насколько серьезно вирус гриппа мутирует в следующем году, может помочь понять, насколько антитела людей, выработанные в этом году, помогут им в борьбе с гриппом через год.
Статью с более подробным разбором нейросети читайте тут. Также у ученых вышла статья в журнале Science.
NeuralCrew: нейросеть, которая основала политическое движение
#ai_fun
С развитием нейронных сетей GPT-2 и GPT-3 для генерации текста люди стали применять их для всего чего угодно. Нейронные сети теперь пишут статьи, генерируют текстовые квесты, выдают себя за Илонов Масков, позволяют вам поговорить с умершими родственниками и делают дизайн сайтов по текстовому описанию.
В общем, делают все, что связано с обработкой текста!
И сегодня мы хотим познакомить вас с еще одним творением GPT-3: нейронка написала манифест нового политического движения в России. Движение назвали NeuralCrew.
Политическая программа, сгенерированная нейросетью, хоть и кажется странной, но оказывается весьма продуманной. Она затрагивает многие вопросы, такие как счастье и права граждан, налоги, культуру, армию и т.д.
Вот, например, как звучит налоговая реформа, предложенная неросетью:
"Наше основное требование — отмена налогов на картошку и капусту. Картошка и капуста — это основа общества. Без них не будет стабильности. Куда бы мы ни пришли, мы всюду видим нехватку одной или нескольких вещей, необходимых для жизни. На русском Севере дети видят дефицит продуктов, которые никто не покупает. Детей заставляют пить водку и смотреть идиотские программы. Хватит это терпеть!"
Полный текст манифеста читайте на сайте проекта LocalCrew.
P.S. Все, о чем написано в посте, сгенерировано нейросетью и не имеет никакой политической и агитационной цели.
Как вам манифест? Может, вы знаете другие интересные примеры генерации текста? Делитесь в комментариях! 🙃
#ai_fun
С развитием нейронных сетей GPT-2 и GPT-3 для генерации текста люди стали применять их для всего чего угодно. Нейронные сети теперь пишут статьи, генерируют текстовые квесты, выдают себя за Илонов Масков, позволяют вам поговорить с умершими родственниками и делают дизайн сайтов по текстовому описанию.
В общем, делают все, что связано с обработкой текста!
И сегодня мы хотим познакомить вас с еще одним творением GPT-3: нейронка написала манифест нового политического движения в России. Движение назвали NeuralCrew.
Политическая программа, сгенерированная нейросетью, хоть и кажется странной, но оказывается весьма продуманной. Она затрагивает многие вопросы, такие как счастье и права граждан, налоги, культуру, армию и т.д.
Вот, например, как звучит налоговая реформа, предложенная неросетью:
"Наше основное требование — отмена налогов на картошку и капусту. Картошка и капуста — это основа общества. Без них не будет стабильности. Куда бы мы ни пришли, мы всюду видим нехватку одной или нескольких вещей, необходимых для жизни. На русском Севере дети видят дефицит продуктов, которые никто не покупает. Детей заставляют пить водку и смотреть идиотские программы. Хватит это терпеть!"
Полный текст манифеста читайте на сайте проекта LocalCrew.
P.S. Все, о чем написано в посте, сгенерировано нейросетью и не имеет никакой политической и агитационной цели.
Как вам манифест? Может, вы знаете другие интересные примеры генерации текста? Делитесь в комментариях! 🙃
IMG_7763.mov
1.5 MB
И снова ожившие фоточки
#tech
Проект MyHeritage представляет Deep Nostalgia: это нейроння сеть, которая оживит ваши фотографии! И не просто сделает фото "объемным", а заставит лица на фото двигаться: улыбаться, моргать, вертеть головой. За исключением нескольких видимых ляпов с волосами и ушами выглядит потрясающе!
MyHeritage — это проект, который помогает людям исследовать историю своего рода. На сайте можно получить доступ к архивным документам о переписях населения, иммиграции, записям о рождении и смерти граждан. Также на сайт можно загрузить свой ДНК-тест и найти близких по генетике людей. Это все поможет вам собрать информацию о своих предках, найти дальних родственников и лучше изучить свой род.
А нейросеть, которая анимирует фотографии, призвана помочь вам оживить черно-белые фото из семейных архивов и сильнее погрузиться в семейную историю =)
#tech
Проект MyHeritage представляет Deep Nostalgia: это нейроння сеть, которая оживит ваши фотографии! И не просто сделает фото "объемным", а заставит лица на фото двигаться: улыбаться, моргать, вертеть головой. За исключением нескольких видимых ляпов с волосами и ушами выглядит потрясающе!
MyHeritage — это проект, который помогает людям исследовать историю своего рода. На сайте можно получить доступ к архивным документам о переписях населения, иммиграции, записям о рождении и смерти граждан. Также на сайт можно загрузить свой ДНК-тест и найти близких по генетике людей. Это все поможет вам собрать информацию о своих предках, найти дальних родственников и лучше изучить свой род.
А нейросеть, которая анимирует фотографии, призвана помочь вам оживить черно-белые фото из семейных архивов и сильнее погрузиться в семейную историю =)
Нейронка знает, на что кого вам нравится смотреть 😏
#paper
Исследователи из университетов Хельсинки и Копенгагена обучили нейронную сеть генерировать привлекательные лица людей.
Как они это сделали:
Сначала ученые сгенерировали множество случайных лиц с помощью обычного ГАНа. Затем эти лица показывали группе из тридцати человек. Людей просили останавливать свое внимание на тех лицах на фото, которые казались им наиболее привлекательными. В ходе эксперимента испытуемым измеряли активность мозга с помощью электроэнцефалографии (ЭЭГ). Эта активность использовалась как мера привлекательности лица для обучения второго ГАНа. В итоге полученная модель научилась генерировать только те лица, которые нравятся людям.
С помощью модели можно сгенерировать лица, которые будут нравиться определенному человеку. Для этого нужно показать испытуемому несколько лиц, снять ЭЭГ мозга человека в то время, когда он смотрит на эти лица, и подстроить выходы ГАНа под активность мозга человека. По сути, ГАН "выделяет" из ЭЭГ информацию, которая говорит о том, какие черты лица нравятся конкретному человеку. А затем генерирует новое лицо, которое объединяет в себе все эти черты.
Идея этой работы очень похожа на идею генерации изображений с условиями. Например, есть ГАны, которые могут сгенерировать лица людей с определенными атрибутами: с очками, длинными волосами, определенным цветом кожи и т.п. Здесь — то же самое: ГАН, который генерирует лица людей с условием привлекательности. Но "привлекательность" лица — более сложное понятие, чем наличие очков или цвета кожи. "Привлекательность" — субъективное понятие, и сильно варьируется от человека к человеку.
Более подробно об устройстве модели и ходе эксперимента читайте в статье и смотрите в видео
Как вам идея? Как думаете, где такой ГАН можно применить?
#paper
Исследователи из университетов Хельсинки и Копенгагена обучили нейронную сеть генерировать привлекательные лица людей.
Как они это сделали:
Сначала ученые сгенерировали множество случайных лиц с помощью обычного ГАНа. Затем эти лица показывали группе из тридцати человек. Людей просили останавливать свое внимание на тех лицах на фото, которые казались им наиболее привлекательными. В ходе эксперимента испытуемым измеряли активность мозга с помощью электроэнцефалографии (ЭЭГ). Эта активность использовалась как мера привлекательности лица для обучения второго ГАНа. В итоге полученная модель научилась генерировать только те лица, которые нравятся людям.
С помощью модели можно сгенерировать лица, которые будут нравиться определенному человеку. Для этого нужно показать испытуемому несколько лиц, снять ЭЭГ мозга человека в то время, когда он смотрит на эти лица, и подстроить выходы ГАНа под активность мозга человека. По сути, ГАН "выделяет" из ЭЭГ информацию, которая говорит о том, какие черты лица нравятся конкретному человеку. А затем генерирует новое лицо, которое объединяет в себе все эти черты.
Идея этой работы очень похожа на идею генерации изображений с условиями. Например, есть ГАны, которые могут сгенерировать лица людей с определенными атрибутами: с очками, длинными волосами, определенным цветом кожи и т.п. Здесь — то же самое: ГАН, который генерирует лица людей с условием привлекательности. Но "привлекательность" лица — более сложное понятие, чем наличие очков или цвета кожи. "Привлекательность" — субъективное понятие, и сильно варьируется от человека к человеку.
Более подробно об устройстве модели и ходе эксперимента читайте в статье и смотрите в видео
Как вам идея? Как думаете, где такой ГАН можно применить?
Привет! Сегодня чуть отвлечемся от темы 😉
Вам пишет Таня Гайнцева — один из преподавателей DLSchool и главный поставщик контента в этом канале =)
Я хочу попросить вас помочь мне с исследованием ВУЗов, где обучают программированию. В чем суть:
Сейчас уже март, и совсем скоро многие начнут выбирать универ, куда будут поступать в сентябре. Многим этот выбор дается нелегко: ВУЗов много, мнений много и они противоречивы. А выбор универа очень важен: он во многом определяет нашу карьеру, а значит, и нашу жизнь.
Я хочу помочь абитуриентам с выбором ВУЗа для постепления. Для этого я создала гуглформу с опросом. Если вы — студент или выпускник любого ВУЗа по специальности, связанной с программированием (даже косвенно) — пожалуйста, заполните эту форму. Это не займет много времени. В ней — вопросы про то, насколько обучение в ВУЗе вам показалось полезным и понравилось вам в целом, а также про то, как вообще стоит выбирать вуз для поступления.
Форма анонимная.
Заполнять можно всем: даже если вы учились в ВУЗе не в России, если только начали учиться (например, сейчас на 1 курсе) и если начали учиться, но по каким-то причинам бросили.
Если вы учились в нескольких ВУЗах — пожалуйста, заполните форму несколько раз, по одному разу на каждый ВУЗ.
Все ответы на форму я проанализирую, напишу выводы в виде поста и открою ответы на форму всем желающим.
Я верю, что, заполнив форму, вы поможете многим в выборе ВУЗа! 😘
Вам пишет Таня Гайнцева — один из преподавателей DLSchool и главный поставщик контента в этом канале =)
Я хочу попросить вас помочь мне с исследованием ВУЗов, где обучают программированию. В чем суть:
Сейчас уже март, и совсем скоро многие начнут выбирать универ, куда будут поступать в сентябре. Многим этот выбор дается нелегко: ВУЗов много, мнений много и они противоречивы. А выбор универа очень важен: он во многом определяет нашу карьеру, а значит, и нашу жизнь.
Я хочу помочь абитуриентам с выбором ВУЗа для постепления. Для этого я создала гуглформу с опросом. Если вы — студент или выпускник любого ВУЗа по специальности, связанной с программированием (даже косвенно) — пожалуйста, заполните эту форму. Это не займет много времени. В ней — вопросы про то, насколько обучение в ВУЗе вам показалось полезным и понравилось вам в целом, а также про то, как вообще стоит выбирать вуз для поступления.
Форма анонимная.
Заполнять можно всем: даже если вы учились в ВУЗе не в России, если только начали учиться (например, сейчас на 1 курсе) и если начали учиться, но по каким-то причинам бросили.
Если вы учились в нескольких ВУЗах — пожалуйста, заполните форму несколько раз, по одному разу на каждый ВУЗ.
Все ответы на форму я проанализирую, напишу выводы в виде поста и открою ответы на форму всем желающим.
Я верю, что, заполнив форму, вы поможете многим в выборе ВУЗа! 😘
👍1
Дипфейки захватили мир.
Если раньше качественные фейковые видео создавались нечасто и в основном для мошеннических целей, то в 2020 году технология вышла из тени.
Теперь дипфейки используются везде. В рекламе, мемах, предвыборных кампаниях и даже для защиты людей от политических преследований. Качество дипфейков при этом вышло на совершенно новый уровень. Если раньше можно было невооруженным глазом заметить "ляпы" и понять, что перед вами — фейк, то сейчас качество дипфейков впечатляет. Только посмотрите на эти видео с "Томом Крузом"! Признайтесь, очень похож на настоящего?
Конечно, мошенники тоже никуда не делись. Скореее, наоборот: улучшение качества дипфейков открыло им новые возможности. Стоит вспомнить случай с поддельным видео CEO компании DBrain, в котором мошенники призывали вкладывать деньги в фейковую компанию. Подробно об этом случае мы писали тут.
Все это вызывает некий диссонанс и даже страх. Неприятно, что мы не можем отличить дипфейк от реальности. Теперь при просмотре любого видео закрадывается мысль: "а вдруг это фейк? Можно верить этой новости или нет?" Создается ощущение, что мы окружены технологиями, что они манипулируют нами. И все, на что мы смотрим — ненастоящее.
А как вы относитесь к дипфейкам?
Как думаете, что будет дальше? Что еще люди научатся "подделывать" с помощью технологий?
Если раньше качественные фейковые видео создавались нечасто и в основном для мошеннических целей, то в 2020 году технология вышла из тени.
Теперь дипфейки используются везде. В рекламе, мемах, предвыборных кампаниях и даже для защиты людей от политических преследований. Качество дипфейков при этом вышло на совершенно новый уровень. Если раньше можно было невооруженным глазом заметить "ляпы" и понять, что перед вами — фейк, то сейчас качество дипфейков впечатляет. Только посмотрите на эти видео с "Томом Крузом"! Признайтесь, очень похож на настоящего?
Конечно, мошенники тоже никуда не делись. Скореее, наоборот: улучшение качества дипфейков открыло им новые возможности. Стоит вспомнить случай с поддельным видео CEO компании DBrain, в котором мошенники призывали вкладывать деньги в фейковую компанию. Подробно об этом случае мы писали тут.
Все это вызывает некий диссонанс и даже страх. Неприятно, что мы не можем отличить дипфейк от реальности. Теперь при просмотре любого видео закрадывается мысль: "а вдруг это фейк? Можно верить этой новости или нет?" Создается ощущение, что мы окружены технологиями, что они манипулируют нами. И все, на что мы смотрим — ненастоящее.
А как вы относитесь к дипфейкам?
Как думаете, что будет дальше? Что еще люди научатся "подделывать" с помощью технологий?
Но у нас есть хорошая новость: дипфейк все же можно распознать.
#ai_inside
(начало — про дипфейки — читайте в посте выше)
Исследователи из университета в Буффало разработали алгоритм, который определяет дипфейки с точностью 94%. Алгоритм основан на сравнении бликов в двух зрачках человека на видео. Дело в том, что на реальных видео отражения в зрачках обоих глаз людей практически идентичны. В фейковых же видео блики сильно отличаются. На фото выше — пример бликов в зрачках реального человека (слева) и фейкового (справа).
Получается, дипфейки в 2021 году все еще неидеальны: все еще есть "ляпы", которые помогают определить, что видео – фейк. Хоть теперь эти "ляпы" можно обнаружить только с помощью технологий, а не простого человеческого взгляда.
Подробнее про алгоритм читайте в статье.
Ну как, стало легче? Как считаете, скоро ли "починят" этот баг и будут создавать дипфейки с правильными бликами в глазах?)
#ai_inside
(начало — про дипфейки — читайте в посте выше)
Исследователи из университета в Буффало разработали алгоритм, который определяет дипфейки с точностью 94%. Алгоритм основан на сравнении бликов в двух зрачках человека на видео. Дело в том, что на реальных видео отражения в зрачках обоих глаз людей практически идентичны. В фейковых же видео блики сильно отличаются. На фото выше — пример бликов в зрачках реального человека (слева) и фейкового (справа).
Получается, дипфейки в 2021 году все еще неидеальны: все еще есть "ляпы", которые помогают определить, что видео – фейк. Хоть теперь эти "ляпы" можно обнаружить только с помощью технологий, а не простого человеческого взгляда.
Подробнее про алгоритм читайте в статье.
Ну как, стало легче? Как считаете, скоро ли "починят" этот баг и будут создавать дипфейки с правильными бликами в глазах?)
Сегодняшний пост не совсем по теме ИИ. Но все же с ИИ он связан.
Алгоритмы искусственного интеллекта глубоко проникли в нашу жизнь. Одно из самых обширных применений ИИ — рекомендательные системы. ИИ решает, какую музыку мы будем слушать, какие фильмы смотреть, какие товары покупать и какой дорогой поедем на работу.
Кажется, что ИИ упрощает нам жизнь и просто дает нам то, что мы хотим. Больше не надо перебирать сотню треков в поиске того, что тебе понравится — ИИ выдаст вам его за один клик. Что в этом плохого?
А плохо то, что мы совсем перестаем оглядываться по сторонам. Один раз выбрав предпочтения, мы позволяем алгоритмам вести нас по этой дороге и дальше, и совсем не пытаемся открыть для себя что-то новое, за пределами уютного мира. Наше поле зрения сужается. Но это неверная стратегия. Возможно, если отойти шаг в сторону от устоявшихся привычек, можно обнаружить куда более крутые вещи: интересную новую музыку, новый стиль в одежде и даже выйти за рамки своих убеждений.
То, что стратегия слепо следовать "лучшей" дорожке — заведомо проигрышная, доказывает то, как ИИ обучается играть в игры. При обучении ИИ играть в шахматы, StarCraft и т.д. используется ε-жадная стратегия. При ε=0.05 это значит, что ИИ только в 95% случаев следует лучшей стратегии, которую он выучил на данный момент. В остальных же 5% случаев ИИ совершает "рандомное" действие. Вдруг оно в итоге приведет к гораздо лучшей стратегии?
ИИ — это вы, а StarCraft — ваша жизнь.
Если этот пост заставил задуматься, то у меня для вас есть кое-что интересное) Мы — далеко не первые, кто задумывается об ограничивающем влиянии алгоритмов на жизнь. Разработчик Max Hawkins задумался об этом всерьез и решил проблему радикально: он разработал алгоритм, который вместо следования его предпочтениям, наоборот, рандомизировал его жизнь. Макс попробовал какое-то время жить с помощью этого алгоритма, и это вылилось в интересный эксперимент и новые открытия в жизни. Подробную историю Макса читайте тут
Ну как? Задумывались об этой стороне влияния технологий на нашу жизнь?
Готовы повторить эксперимент Макса? 😉
Алгоритмы искусственного интеллекта глубоко проникли в нашу жизнь. Одно из самых обширных применений ИИ — рекомендательные системы. ИИ решает, какую музыку мы будем слушать, какие фильмы смотреть, какие товары покупать и какой дорогой поедем на работу.
Кажется, что ИИ упрощает нам жизнь и просто дает нам то, что мы хотим. Больше не надо перебирать сотню треков в поиске того, что тебе понравится — ИИ выдаст вам его за один клик. Что в этом плохого?
А плохо то, что мы совсем перестаем оглядываться по сторонам. Один раз выбрав предпочтения, мы позволяем алгоритмам вести нас по этой дороге и дальше, и совсем не пытаемся открыть для себя что-то новое, за пределами уютного мира. Наше поле зрения сужается. Но это неверная стратегия. Возможно, если отойти шаг в сторону от устоявшихся привычек, можно обнаружить куда более крутые вещи: интересную новую музыку, новый стиль в одежде и даже выйти за рамки своих убеждений.
То, что стратегия слепо следовать "лучшей" дорожке — заведомо проигрышная, доказывает то, как ИИ обучается играть в игры. При обучении ИИ играть в шахматы, StarCraft и т.д. используется ε-жадная стратегия. При ε=0.05 это значит, что ИИ только в 95% случаев следует лучшей стратегии, которую он выучил на данный момент. В остальных же 5% случаев ИИ совершает "рандомное" действие. Вдруг оно в итоге приведет к гораздо лучшей стратегии?
ИИ — это вы, а StarCraft — ваша жизнь.
Если этот пост заставил задуматься, то у меня для вас есть кое-что интересное) Мы — далеко не первые, кто задумывается об ограничивающем влиянии алгоритмов на жизнь. Разработчик Max Hawkins задумался об этом всерьез и решил проблему радикально: он разработал алгоритм, который вместо следования его предпочтениям, наоборот, рандомизировал его жизнь. Макс попробовал какое-то время жить с помощью этого алгоритма, и это вылилось в интересный эксперимент и новые открытия в жизни. Подробную историю Макса читайте тут
Ну как? Задумывались об этой стороне влияния технологий на нашу жизнь?
Готовы повторить эксперимент Макса? 😉
CLIP: соединяя изображения и текст
#paper
Нейронные сети отлично показывают себя в задачах компьютерного зрения (CV) и обработки естественного языка (NLP). При этом для обработки изображений и текста исторически используются разные архитектуры сетей, заточенные именно под текст или именно под картинки.
Но есть огромный класс задач, где требуется одновременное понимание и изображений, и текстов. Это, например, video captioning (генерация описаний к видео) или OCR (распознавание текста на фото). Здесь возникает потребность изобретать новые архитектуры сетей, способные комбинировать понимание и текста, и видео.
Такие системы называются мультимодальными: способными работать сразу с несколькими модальностями. Модельности — текст, звук, изорбражение, видео и т.д.
Одна из лучших мультимодальных нейросистем на данный момент — CLIP от OpenAI.
Идея ее простая:
Есть датасет картинок и текстовых описаний к ним. CLIP обучает две нейросети обрабатывать картинки и описания отдельно. Далее мы учим сеть так, чтобы вектор (эмбеддинг), выданный сетью на картинку, был похож на вектор, выданный сетью на описание этой картинки, и далек от векторов, выданных сетью на описания других картинок (см. левую часть картинки выше).
Другими словами, сеть обучается по картинке понимать, какое из множества текстовых описаний соответствует именно этой картинке.
Такое вот простое обучение сети позволяет применять CLIP к множеству задач, связанных с картинками и текстом. К примеру, CLIP легко дообучить на решение задачи классификации ImageNet. Для этого нужно превратить классы картинок из слов "птица", "корабль" в текст: "это фотография птицы", "это фотография корабля". Тогда задача классификации решается так: подаем на вход CLIP картинку из ImageNet и все тексты, полученные из классов ImageNet. Текст, вектор которого будет больше всего похож на вектор картинки, и содержит в себе правильный класс (см. правую часть картинки выше).
CLIP показывает отличные результаты на многих задачах CV и NLP. Более того, векторы картинок и текстов у CLIP действительно хорошо выучивают "смысл" картинок и текстов. Лучше, чем другие мультимодальные модели.
Подробнее про этот "смысл" мы расскажем в следующем посте
#paper
Нейронные сети отлично показывают себя в задачах компьютерного зрения (CV) и обработки естественного языка (NLP). При этом для обработки изображений и текста исторически используются разные архитектуры сетей, заточенные именно под текст или именно под картинки.
Но есть огромный класс задач, где требуется одновременное понимание и изображений, и текстов. Это, например, video captioning (генерация описаний к видео) или OCR (распознавание текста на фото). Здесь возникает потребность изобретать новые архитектуры сетей, способные комбинировать понимание и текста, и видео.
Такие системы называются мультимодальными: способными работать сразу с несколькими модальностями. Модельности — текст, звук, изорбражение, видео и т.д.
Одна из лучших мультимодальных нейросистем на данный момент — CLIP от OpenAI.
Идея ее простая:
Есть датасет картинок и текстовых описаний к ним. CLIP обучает две нейросети обрабатывать картинки и описания отдельно. Далее мы учим сеть так, чтобы вектор (эмбеддинг), выданный сетью на картинку, был похож на вектор, выданный сетью на описание этой картинки, и далек от векторов, выданных сетью на описания других картинок (см. левую часть картинки выше).
Другими словами, сеть обучается по картинке понимать, какое из множества текстовых описаний соответствует именно этой картинке.
Такое вот простое обучение сети позволяет применять CLIP к множеству задач, связанных с картинками и текстом. К примеру, CLIP легко дообучить на решение задачи классификации ImageNet. Для этого нужно превратить классы картинок из слов "птица", "корабль" в текст: "это фотография птицы", "это фотография корабля". Тогда задача классификации решается так: подаем на вход CLIP картинку из ImageNet и все тексты, полученные из классов ImageNet. Текст, вектор которого будет больше всего похож на вектор картинки, и содержит в себе правильный класс (см. правую часть картинки выше).
CLIP показывает отличные результаты на многих задачах CV и NLP. Более того, векторы картинок и текстов у CLIP действительно хорошо выучивают "смысл" картинок и текстов. Лучше, чем другие мультимодальные модели.
Подробнее про этот "смысл" мы расскажем в следующем посте
👍3
Нейросети становятся более похожими на мозг человека
#paper #ai_inside
Ученые из OpenAI, которые придумали нейросеть CLIP (что это за нейросеть, мы писали в посте выше), выяснили, что у модели есть мультимодальные нейроны. Это нейроны, которые реагируют на информацию, представленную в разных формах: как в виде текста, так и в виде изображения.
Почему это круто:
Обычно у нейросетей, которые работают сразу с несколькими модальностями — скажем, с текстом и видео — есть определенные "части", которые отвечают за конкретную модальность. Одна часть нейросети обрабатывает текст, другая — картинки. Более того, та часть сети, которая хорошо работает с фотографиями лиц, очень плохо реагирует на рисованные картинки лиц. То есть, каждая часть сети очень сильно заточена под свою конкретную задачу, и даже малейший шаг в сторону совершенно сбивает сеть с толку.
Но у CLIP все иначе. Там, оказывается, есть нейроны, которые одинаково хорошо реагируют и на картинки, и на текст. Иными словами, это "мультимодальные" нейроны, способные обрабатывать информацию, представленную в разном виде.
Пример: возьмем фото Человека-паука и фото с текстом, в котором есть слово "Человек-Паук". При прогоне этих картинок через сеть выясняется, что один из нейронов сети одинаково сильно активируется на обе картинки. Ученые назвали этот нейрон "нейроном Человека-паука".
Точно так же можно выделить в сети нейроны, реагирующие на другие понятия: "Хэлли Берри", "человеческое лицо" и т.п.
Получается, что нейроны CLIP оперируют семантическими понятиями, идеями, а не чисто формами и текстурами изображений. Нейронка вышла на новый уровень осознания сущностей. Ничего подобного не наблюдалось ни у одной неросети до CLIP.
На практике также отмечается, что векторы, получаемые из текста и картинок моделью CLIP, лучше отражают смысл слов и изображений, чем векторы других моделей.
Что еще интересно: такие же "мультимодальные" нейроны есть в мозге человека. Это выяснили еще 15 лет назад с помощью электродов, подключаемых к головам людей. Таким образом, искуственный интеллект в лице CLIP стал сделал большой шаг на пути к реальному "интеллекту" 😉
Подробнее читайте в блогпосте OpenAI.
#paper #ai_inside
Ученые из OpenAI, которые придумали нейросеть CLIP (что это за нейросеть, мы писали в посте выше), выяснили, что у модели есть мультимодальные нейроны. Это нейроны, которые реагируют на информацию, представленную в разных формах: как в виде текста, так и в виде изображения.
Почему это круто:
Обычно у нейросетей, которые работают сразу с несколькими модальностями — скажем, с текстом и видео — есть определенные "части", которые отвечают за конкретную модальность. Одна часть нейросети обрабатывает текст, другая — картинки. Более того, та часть сети, которая хорошо работает с фотографиями лиц, очень плохо реагирует на рисованные картинки лиц. То есть, каждая часть сети очень сильно заточена под свою конкретную задачу, и даже малейший шаг в сторону совершенно сбивает сеть с толку.
Но у CLIP все иначе. Там, оказывается, есть нейроны, которые одинаково хорошо реагируют и на картинки, и на текст. Иными словами, это "мультимодальные" нейроны, способные обрабатывать информацию, представленную в разном виде.
Пример: возьмем фото Человека-паука и фото с текстом, в котором есть слово "Человек-Паук". При прогоне этих картинок через сеть выясняется, что один из нейронов сети одинаково сильно активируется на обе картинки. Ученые назвали этот нейрон "нейроном Человека-паука".
Точно так же можно выделить в сети нейроны, реагирующие на другие понятия: "Хэлли Берри", "человеческое лицо" и т.п.
Получается, что нейроны CLIP оперируют семантическими понятиями, идеями, а не чисто формами и текстурами изображений. Нейронка вышла на новый уровень осознания сущностей. Ничего подобного не наблюдалось ни у одной неросети до CLIP.
На практике также отмечается, что векторы, получаемые из текста и картинок моделью CLIP, лучше отражают смысл слов и изображений, чем векторы других моделей.
Что еще интересно: такие же "мультимодальные" нейроны есть в мозге человека. Это выяснили еще 15 лет назад с помощью электродов, подключаемых к головам людей. Таким образом, искуственный интеллект в лице CLIP стал сделал большой шаг на пути к реальному "интеллекту" 😉
Подробнее читайте в блогпосте OpenAI.
Недавно мы предлагали вам послушать выпуск подкаста "Запуск завтра" о том, как искусственный интеллект помогает выращивать марихуану и лечить рак. Если пропустили, то обязательно послушайте: вот ссылка на пост.
#podcast
Сегодня хотим рассказать про еще один подкаст от той же студии, которая выпускает "Запуск завтра". Это подкаст "Вы находитесь здесь".
#подкаст
В отличие от "запуска завтра", этот подкаст полностью посвящен искусственному интеллекту. В нем простым языком объясняют сложные процессы обучения умных машин и рассказывают, какое будущее ждет ИИ. А также расскажут, что о людях думает умная колонка, зачем давать роботам цифровые эмоции, способна ли нейросеть действительно понять человека и чьим голосом на самом деле разговаривал Стивен Хокинг.
Послушать подкаст можно здесь
#podcast
Сегодня хотим рассказать про еще один подкаст от той же студии, которая выпускает "Запуск завтра". Это подкаст "Вы находитесь здесь".
#подкаст
В отличие от "запуска завтра", этот подкаст полностью посвящен искусственному интеллекту. В нем простым языком объясняют сложные процессы обучения умных машин и рассказывают, какое будущее ждет ИИ. А также расскажут, что о людях думает умная колонка, зачем давать роботам цифровые эмоции, способна ли нейросеть действительно понять человека и чьим голосом на самом деле разговаривал Стивен Хокинг.
Послушать подкаст можно здесь
"Ну там ээ дерево живое и енот живой"
#tech
Бывали в ситуации, когда помните, о чем фильм, но не можете вспомнить название? Мучительная история. К счастью, нейронные сети могут нам в этом помочь =)
Яндекс разработал алгоритм поиска фильмов по его характеристикам. Введите в строку поиска Яндекса то, что помните о фильме, и поиск поймет, что за фильм вы ищете. Например, по фразе "фильм, где человек оббежал всю Америку", поиск выдает: да это же "Форрест Гамп"!
Фильм найдется даже по самым замысловатым запросам: "Чтобы поиск нашёл фильм, не обязательно помнить его сюжет, достаточно указать в запросе характеристики героев, интригу, конфликт или отдельный эпизод. Каким бы нелепым не было описание, поиск предложит варианты." — пишет Яндекс.
Подробнее про алгоритм читайте в блопосте Яндекса.
Кстати, еще у Яндекса есть интересное исследование о том, с помощью каких запросов пользователи ищут те или иные фильмы. Для фильмов разных стран и разных жанров составили топ самых часто встречающихся ключевых слов: персонажей, действий, мест. Вышло, что в индийских фильмах чаще всего фигурируют танцы и свадьбы, а в русских — менты и тюрьма. В такой вот грустной стране живем.
Больше информации об исследовании — тут
#tech
Бывали в ситуации, когда помните, о чем фильм, но не можете вспомнить название? Мучительная история. К счастью, нейронные сети могут нам в этом помочь =)
Яндекс разработал алгоритм поиска фильмов по его характеристикам. Введите в строку поиска Яндекса то, что помните о фильме, и поиск поймет, что за фильм вы ищете. Например, по фразе "фильм, где человек оббежал всю Америку", поиск выдает: да это же "Форрест Гамп"!
Фильм найдется даже по самым замысловатым запросам: "Чтобы поиск нашёл фильм, не обязательно помнить его сюжет, достаточно указать в запросе характеристики героев, интригу, конфликт или отдельный эпизод. Каким бы нелепым не было описание, поиск предложит варианты." — пишет Яндекс.
Подробнее про алгоритм читайте в блопосте Яндекса.
Кстати, еще у Яндекса есть интересное исследование о том, с помощью каких запросов пользователи ищут те или иные фильмы. Для фильмов разных стран и разных жанров составили топ самых часто встречающихся ключевых слов: персонажей, действий, мест. Вышло, что в индийских фильмах чаще всего фигурируют танцы и свадьбы, а в русских — менты и тюрьма. В такой вот грустной стране живем.
Больше информации об исследовании — тут
Monkey MindPong
#tech
Компания NeuralLink показала видео, где обезъяна играет в компьютерную игру с помощью чипа, вживленного ей в голову. Без рук!
NeuralLink — компания, основанная Илоном Маском, которая занимается нейротехнологиями. Конкретнее: имплантированием нейрокомпьютеров в мозг.
Цель NeuralLink в краткосрочной перспективе — помочь парализованным людям силой мысли управлять гаджетами. Также планируется, что нейрочипы будут заменять пораженные участки спинного мозга человека и ускорят реабилитацию парализованных людей.
Ну а в долгосрочной перспективе цель NeuralLink — с помощью нейрочипов в мозге создать усовершенствованную версию человека =)
Эксперимент с обезъяной — первый крупный успех. Подробнее про эксперимент читайте в статье NeuralLink.
"Ну а при чем тут нейронки и ИИ?" — спросите вы. Все просто: машинное обучение часто используется в нейрочипах для распознавания активности мозга. Так что нас ждёт удивительное будущее: на стыке техники и нейросетей :)
#tech
Компания NeuralLink показала видео, где обезъяна играет в компьютерную игру с помощью чипа, вживленного ей в голову. Без рук!
NeuralLink — компания, основанная Илоном Маском, которая занимается нейротехнологиями. Конкретнее: имплантированием нейрокомпьютеров в мозг.
Цель NeuralLink в краткосрочной перспективе — помочь парализованным людям силой мысли управлять гаджетами. Также планируется, что нейрочипы будут заменять пораженные участки спинного мозга человека и ускорят реабилитацию парализованных людей.
Ну а в долгосрочной перспективе цель NeuralLink — с помощью нейрочипов в мозге создать усовершенствованную версию человека =)
Эксперимент с обезъяной — первый крупный успех. Подробнее про эксперимент читайте в статье NeuralLink.
"Ну а при чем тут нейронки и ИИ?" — спросите вы. Все просто: машинное обучение часто используется в нейрочипах для распознавания активности мозга. Так что нас ждёт удивительное будущее: на стыке техники и нейросетей :)