еще один видосик, теперь от Суцкевера, во время присвоения почетной докторской степени в университете Торонто, он выдал довольно пугающий прогноз, что мир изменится до неузнаваемости; в частности он говорит, что ИИ сможет выполнить любую работу, которую делает человек, и по его прикидкам это будет реальностью уже в течение 10 лет
я склонен согласиться с Ильей Ефимовичем, хотя сможет не значит будет; на мой взгляд тут будет такая же история, что и с роботами в 70-х годах: если кто не в курсе, то массовая роботизация началась по всему миру (в том числе у нас) в 70-е годы, но довольно быстро заглохла, т.к. оказалось, что человек-рабочий (например, в Китае) дешевле; здесь будет примерно то же самое - да, теоретически ИИ сможет, например, проконсультировать вас, как устранить засор в кухонной раковине, но скорее всего проще и дешевле будет все равно вызвать сантехника; то есть да, наша жизнь поменяется, но не в том плане, что вообще не нужно будетумирать ничего делать
я склонен согласиться с Ильей Ефимовичем, хотя сможет не значит будет; на мой взгляд тут будет такая же история, что и с роботами в 70-х годах: если кто не в курсе, то массовая роботизация началась по всему миру (в том числе у нас) в 70-е годы, но довольно быстро заглохла, т.к. оказалось, что человек-рабочий (например, в Китае) дешевле; здесь будет примерно то же самое - да, теоретически ИИ сможет, например, проконсультировать вас, как устранить засор в кухонной раковине, но скорее всего проще и дешевле будет все равно вызвать сантехника; то есть да, наша жизнь поменяется, но не в том плане, что вообще не нужно будет
💯19👍8😁3🔥2❤1
Microsoft представил языковую модель Mu; это кодировщик-декодировщик (что само по себе интересно, T5 как-то утратила актуальность) размером, как большой BERT - 330 млн параметров, в наше время это ни о чем; они оптимизировали ее для процессоров Intel, AMD и Qualcomm (последнее - для своих планшетов Surface); применение у нее стандартное - QA (первая картинка), но еще и Function Calling (они это называют агент для настроек, вторая картинка); по качеству она несколько хуже Phi 3B (третья картинка), интересно еще, что они помнят про свой кодовый бенчмарк CodeXGLUE, на нем давно никто не замерялся
🔥5❤2👍1
к вопросу об опенсорсе и закрытости AI-экосистем; на мой взгляд все развивается закономерно в эту сторону
сама статья кстати интересная, посвящена тому, как эффективно считать матричные умножения в 4-битных матрицах
сама статья кстати интересная, посвящена тому, как эффективно считать матричные умножения в 4-битных матрицах
💯2
сегодня хочу вам представить первый выпуск подкаста "Капитанский мостик", он посвящен важным новостям прошедшей недели; делаем его я и Дмитрий Колодезев; видео тут:
VK Video
YouTube
присылайте новости для обсуждения в канал "Дата-капитаны" в mattermost (авторизуйтесь через ODS.ai)
VK Video
YouTube
присылайте новости для обсуждения в канал "Дата-капитаны" в mattermost (авторизуйтесь через ODS.ai)
🔥20👍7❤3
как сейчас принято говорить, пу-пу-пу; подозреваю, что масштаб проблемы в разы больший; хотя рассчитано на самых ленивых ревьюверов, но я уже говорил, это труд неблагодарный, так что многие стремятся его спихнуть на LLM
😁17
Microsoft выкатили модель MAI-DxO (видео ее работы идет первым), внутри она собирает консилиум из агентов для принятия решения о постановке диагноза (вторая картинка); хочу обратить внимание на то, что они делают анализ затрат, а мы с коллегами проводили конкурс, где такая задача была поставлена (и даже решена!) для легочных заболеваний, еще три года назад; коллеги из Сеченовского университета этим продолжают заниматься, насколько я понимаю
👍10❤1
интересное происходит, Huawei опенсорснула свою PanGu, а почти сразу после этого появились непонятные люди, которые назвали себя HonestyAGI, и написали, что PanGu - это копия Qwen; сейчас репозиторий с кодом недоступен, я не догадался его сохранить для истории, так что есть только скрины из репорта
насколько эта история правдива, я не берусь сказать, какая-то она мутная: с одной стороны предположить, что Huawei взяли Qwen для тренировки своей модели - это очень похоже на правду, в конце концов у нас Яндекс и Т-банк так сделали; с другой стороны, принципиальным отличием является то, что Huawei позиционировала свою модель, как натренированную с нуля на своих процессорах, и этот релиз должен был стать их рекламой
в общем пиар не особо получился, по крайней мере за пределами Китая; хотя я не специалист по пиару, так что может все нормально: крупные компании много раз садились в лужу, но это не мешало им дальше существовать, достаточно вспомнить Tay от Microsoft
насколько эта история правдива, я не берусь сказать, какая-то она мутная: с одной стороны предположить, что Huawei взяли Qwen для тренировки своей модели - это очень похоже на правду, в конце концов у нас Яндекс и Т-банк так сделали; с другой стороны, принципиальным отличием является то, что Huawei позиционировала свою модель, как натренированную с нуля на своих процессорах, и этот релиз должен был стать их рекламой
в общем пиар не особо получился, по крайней мере за пределами Китая; хотя я не специалист по пиару, так что может все нормально: крупные компании много раз садились в лужу, но это не мешало им дальше существовать, достаточно вспомнить Tay от Microsoft
🤔4👍3💯3
тут пришло две связанных одной темой, но отличающихся последствиями новости: с одной стороны - в Мариинском театре состоялась премьера оперы, которая была дописана с участием ИИ; с другой - группу Velvet Sundown подозревают в том, что вся их музыка сгенерированная
так и хочется написать "два мира - два Шапиро", но это - мем времен раннего палеозоя, нынче такие не в моде, поэтому я ограничился заглавной картинкой
если серьезно, то на мой взгляд все сводится к давней мудрости "красота - в глазах смотрящего"; ИИ - это инструмент для человека (композитора в этом случае); если пользоваться аналогией с землекопанием, то сначала копали руками (ручкой на бумаге), потом стали лопатой (ПО), а сейчас появились экскаваторы (ИИ)
в конце концов, как мы знаем, между созданием ИИ и созданием музыки не такая большая разница
так и хочется написать "два мира - два Шапиро", но это - мем времен раннего палеозоя, нынче такие не в моде, поэтому я ограничился заглавной картинкой
если серьезно, то на мой взгляд все сводится к давней мудрости "красота - в глазах смотрящего"; ИИ - это инструмент для человека (композитора в этом случае); если пользоваться аналогией с землекопанием, то сначала копали руками (ручкой на бумаге), потом стали лопатой (ПО), а сейчас появились экскаваторы (ИИ)
в конце концов, как мы знаем, между созданием ИИ и созданием музыки не такая большая разница
👍13❤2
не успел отгреметь скандал с PanGu и Qwen; а уже подоспел новый: появился некий человек, который утверждает, что работает над PanGu в ужасных условиях (6 дней в неделю, отдельно от семьи в другом городе) - выдержка из его письма на первой картинке; для сравнения привел вторую картинку, которая описывает ситуацию в офисе xAI; противостояние в сфере ИИ не снижает накала
👀8👍2🤣2🎃2
сегодня вместо традиционного субботнего мема порекомендую отличный рассказ моей знакомой на актуальную тему "обучения ифритов для перевода со староиберийского на полихтонский"
🔥2👍1
сегодня второй выпуск подкаста "Капитанский мостик", он посвящен важным новостям прошедшей недели; делаем его я и Дмитрий Колодезев; видео тут:
VK Video
YouTube
присылайте новости для обсуждения в канал "Дата-капитаны" в mattermost (авторизуйтесь через ODS.ai)
VK Video
YouTube
присылайте новости для обсуждения в канал "Дата-капитаны" в mattermost (авторизуйтесь через ODS.ai)
🔥5👌1
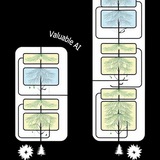
коллеги из Google выпустили статью с интересной идеей: вернуться к концепции encoder-decoder (недавно такую модель выпустил Microsoft); суть подхода изложена на первой картинке - берем готовую декодерную модель, в их случае Gemma, и инициализируем все веса декодировщика из нее, веса кодировщика также берутся из декодерной модели, кроме весов внимания, которое учится с нуля; в качестве преимущества подхода заявляется возможность создания несбалансированных моделей с большим кодировщиком и маленьким декодировщиком
на второй картинке представлены результаты; PT - это набор стандартных датасетов, типа SuperGLUE, а IT - инструкционных; и вот тут для меня начинаются проблемы - получается, что модель 9+2B хуже, чем обычная 9B; этот аспект авторы как-то обошли стороной (показал стрелочками); интересно, что на SuperGLUE этого эффекта не наблюдается (нижняя часть второй картинки)
@valuableai
на второй картинке представлены результаты; PT - это набор стандартных датасетов, типа SuperGLUE, а IT - инструкционных; и вот тут для меня начинаются проблемы - получается, что модель 9+2B хуже, чем обычная 9B; этот аспект авторы как-то обошли стороной (показал стрелочками); интересно, что на SuperGLUE этого эффекта не наблюдается (нижняя часть второй картинки)
@valuableai
🔥5🤔4