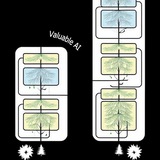
с моим коллегой произошла типичная история кражи идеи из головы: вышла работа, где предлагается концепция soft thinking (первая картинка); простыми словами это про то, что рассуждения в виде слов ограничивают выразительную способность модели (думаю, что и человека тоже), если это ограничение снять (вторая картинка), то результата можно достичь быстрее (третья картинка)
P.S. сейчас пошла мода делать одностраничные сайты для статей, где выкладывать основные результаты с красивыми картинками,я такие сайты называю комиксами, и только приветствую их появление, т.к. доходчивость у них действительно больше
P.S. сейчас пошла мода делать одностраничные сайты для статей, где выкладывать основные результаты с красивыми картинками,
❤12👍7
завтра буду участвовать в онлайн-дискуссии в рамках конференции "AI-инструменты и разработка"; дискуссия будет под лозунгом «ИИ в разработке: мечта менеджера, кошмар инженера»; участие в конференции бесплатное, начало дискуссии в 14:10, регистрация тут
👍7❤2
Google выпустил AI Edge Gallery - это приложение под андроид, которое позволяет скачивать модели с HuggingFace (первая картинка) и запускать их на мобильном устройстве (вторая картинка)
на мой взгляд тут уместно вспомнить уже классическую историю про сравнение с Apollo Guidance Computer (третья картинка): у него было 32 кб памяти и 43 Гц частоты (именно Герца без приставок), для сравнения у последнего Google Pixel 16 Гб памяти и 3,4 ГГц частоты (на 8 ядрах), что делает его примерно в 1 000 000 раз мощнее; это к вопросу об эффективном программировании; зато на нем можно LLM крутить, да
на мой взгляд тут уместно вспомнить уже классическую историю про сравнение с Apollo Guidance Computer (третья картинка): у него было 32 кб памяти и 43 Гц частоты (именно Герца без приставок), для сравнения у последнего Google Pixel 16 Гб памяти и 3,4 ГГц частоты (на 8 ядрах), что делает его примерно в 1 000 000 раз мощнее; это к вопросу об эффективном программировании; зато на нем можно LLM крутить, да
💯10❤2
Эрик Шмит говорит, что 99 процентов электроэнергии будет использоваться под нужды ИИ; мы недавно эту тему обсуждали; как я понимаю, про США он вот такое говорит:
тогда за полтора года надо добавить 2,5% процента от общей генерации (она составляла 1188 ГВт в 2023 году, согласно EIA) и еще 5% за следующие 3 года, темпы прямо скажем стахановские
"Many people project demand for our industry will go from 3 percent to 99 percent of total generation... an additional 29 gigawatts by 2027 and 67 more gigawatts by 2030,"he said.
тогда за полтора года надо добавить 2,5% процента от общей генерации (она составляла 1188 ГВт в 2023 году, согласно EIA) и еще 5% за следующие 3 года, темпы прямо скажем стахановские
Futurism
Former Google CEO Tells Congress That 99 Percent of All Electricity Will Be Used to Power Superintelligent AI
Billionaire tech tycoon Eric Schmidt told Congress that 99 percent of electricity will soon be used to power AI.
👍2⚡1
я много лет пользуюсь StackOverflow для вопросов по программированию, в том числе по TeX, а сегодня я заметил шапку сайта; эльфийские письмена, да, именно так нормальные люди воспринимают эти наши научные статьи
😁25😐1
оказывается, у нас тоже не отстают в плане внедрения ИИ в медицину от Саудовской Аравии (ну ладно, отстают, но в этом случае, я считаю, поспешать нужно медленно)
кстати, про внедрение ИИ у нас в судопроизводство тоже была не так давно новость
ФГБНУ "НИИГБ имени Краснова" готовится внедрить передовую систему диагностики, мониторинга и лечения возрастных заболеваний сетчатки на основе ИИ-технологий, которая опирается на обширную базу офтальмологических медицинских данных
кстати, про внедрение ИИ у нас в судопроизводство тоже была не так давно новость
TACC
НИИГБ им. Краснова готовится внедрить систему диагностики сетчатки на основе ИИ-технологий
Технологии будут основываться на клинической базе, которая позволяет создавать системы, способные ставить очень точный диагноз
❤4👍4
мало кто знает, но я в бакалавриате занимался компиляторами, так что новая работа (что интересно от коллег из Visa) меня сразу заинтересовала; суть работы показана на первой картинке, а на второй - черрипикнутый результат; на их наборе данных они смогли ускорить исполнение кода вполовину относительно
на третьей картинке результаты тестирования, меня там смущает то, что сравниваются с другими моделями, а не с тем же
gcc -O3; я в свое время делал доклад про написание программ с помощью трансформеров, вот тут зашли с другой стороны в ту же рекуна третьей картинке результаты тестирования, меня там смущает то, что сравниваются с другими моделями, а не с тем же
gcc, у которого есть под сотню разных доступных оптимизаций (O3 включает далеко не все); второй пункт - то, что при применении LLM к бинарнику, выход может быть поломанным - примерно в 4% случаев; этим и gcc грешит, но с ним напрямую не сравниваются; в статье есть отдельный раздел про то, что LLM пока не могут заменить компиляторы, что видно и по результатам - без готового бинарника напрямую из С они рабочий ассемблер почти не могут сгенерировать👍11✍5🔥3
к слову о поспешать медленно, недавно была новость о том, что в США госорганизация (президенстская комиссия Make America Healthy Again) выпустила отчет о здоровье детей как минимум частично сгенерированный LLM; там тут же обнаружили галлюцинации с несуществующими цитатами, страшно подумать, что там может быть еще
NY Times
White House Health Report Included Fake Citations
A report on children’s health released by the Make America Healthy Again Commission referred to scientific papers that did not exist.
🌚6😢3👍2
во Вьетнаме осенью (25-26 октября) будет проходить дружественная конференция FPT International Conference on Emerging Trends in Computing, посвященная в основном AI; вот темы:
предполагается публикация в индексируемом Scopus журнале, крайний срок подачи 30 июня; подаваться тут
Data Availability and Quality
Data Collection and Annotation
Synthetic Data Generation
Energy Efficiency and Optimization
Efficient Algorithms and Models
Model Compression and Quantization
Edge Computing and Decentralization
Edge AI
Federated Learning
NLP for Low-resource Languages
Transfer Learning and Domain Adaptation
Unsupervised and Semi-supervised Learning for Low-resource NLP
Multi-lingual and Cross-lingual NLP
Image and Video Understanding
Deep Learning for Visual Understanding
Face and Expression Recognition
Content-Based Indexing, Search, and Retrieval
Machine Learning Applications
Medicine, Health, Bioinformatics and Systems Biology
Industrial and Engineering Applications
Smart Cities and Autonomous Driving
предполагается публикация в индексируемом Scopus журнале, крайний срок подачи 30 июня; подаваться тут
❤4👍3🔥1
пришла новость, девелопер MR Group будет внедрять Алису, как "цифрового консьержа"; с одной стороны - дело хорошее, но меня это все несколько смущает в свете недавних новостей про то, что Claude будет автоматически оповещать соответствующие органы, если пользователь будет запрашивать что-то противозаконное; я готов поставить на то, что так сказать лучшие практики Яндекс переймет у коллег из-за океана очень быстро, как не раз уже бывало
Коммерсантъ
«Алисе» дадут ключи от квартиры
«Яндекс» договорился с MR Group о внедрении своего ИИ в новостройки
🫡7👍4🔥2🤔2👎1🤯1😱1
сообщают, что устав бороться с ChatGPT преподаватели в США начали переходить обратно на тетради, в смысле на прием работ в письменной форме; тут велик соблазн сказать, что это современные луддиты, но я думаю, что тут скорее уместна другая аналогия - с калькуляторами в российских школах; когда я учился их еще запрещали, сейчас, насколько я знаю, разрешили
проблема не в калькуляторах, а в том, чему и как мы учимся; учиться писать тексты важно, но важно уметь именно выражать свои мысли; в выражении принципиально важна логическая структура, а саму техническую работу по красивым формулировкам можно оставить и ChatGPT; на мой взгляд тут полная аналогия с программированием
@valuableai
проблема не в калькуляторах, а в том, чему и как мы учимся; учиться писать тексты важно, но важно уметь именно выражать свои мысли; в выражении принципиально важна логическая структура, а саму техническую работу по красивым формулировкам можно оставить и ChatGPT; на мой взгляд тут полная аналогия с программированием
@valuableai
👍8🤔2👎1😱1🤣1
к вопросу о технологической нейтральности: официально объявлено о создании подразделения “Executive Innovation Corps” в Армии США; туда войдут директора топовых ИИ-компаний
On Friday, the service is set to swear-in Meta’s chief technology officer Andrew Bosworth, OpenAI’s chief product officer Kevin Weil, Palantir’s CTO Shyam Sankar and Bob McGrew, an advisor at Thinking Machines Lab who was previously OpenAI’s chief research officer.
🤔7💯1
недавно в новостях привели фразу Сундара Пичаи (CEO Google):
первым это определение придумал Андрей Карпаты (автор термина вайб-кодинг), но на мой взгляд тут интересно не авторство, а семантика термина: jagged переводится, как "зазубренный" и смысл такого определения в том, что современные ИИ-модели очень хороши в чем-то одном, но при этом совершенно элементарные вещи делать не способны (типа посчитать, сколько "r" в слове "strawberry"); и тут вступает в игру уже семантика русского языка, в котором есть близкое по звучанию слово "зубрежка", обозначающее заучивание ответов; и как раз зубрежка лучше всего подходит для описания процесса обучения современных LLM; так чтопредлагаю все ИИ-модели называть зубрами тут уместно вспомнить, высказывание Козьмы Пруткова: "специалист подобен флюсу, и полнота его одностороння"
Google CEO Sundar Pichai says There's a new term for the current phase of AI: "AJI."
It stands for "artificial jagged intelligence," and is the precursor to AGI.
первым это определение придумал Андрей Карпаты (автор термина вайб-кодинг), но на мой взгляд тут интересно не авторство, а семантика термина: jagged переводится, как "зазубренный" и смысл такого определения в том, что современные ИИ-модели очень хороши в чем-то одном, но при этом совершенно элементарные вещи делать не способны (типа посчитать, сколько "r" в слове "strawberry"); и тут вступает в игру уже семантика русского языка, в котором есть близкое по звучанию слово "зубрежка", обозначающее заучивание ответов; и как раз зубрежка лучше всего подходит для описания процесса обучения современных LLM; так что
👍8🤔5🔥3❤2💯2
кто про что, а я про RNN-ки; тут вышла работа, в которой показано, что постепенное обучение (c подкреплением, конечно) сначала подзадачам, а потом на основе них - сложным задачам (первая картинка), эффективно, как для животных (вторая картинка), так и для RNN (третья картинка, обратите внимание на ушки у компьютера); само по себе это не новость, но в этой работе показано, что именно сам процесс обучения у животных и RNN схож
🔥19👍2