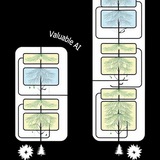
идет подъем интереса к рекуррентным моделям, вот и коллеги из Sakana AI подключились (они периодически выдают что-то интересное, в прошлый раз было про искусственного ученого), они представили архитектуру под сбивающим с названия названием Continuous Thought Machines; по названию я бы предположил, что это одна из современных рассуждающих моделей; но нет, суть подхода показана на картинке (хотя все равно там не особо понятно), больше все мне этот подход напомнил Structured State Space models, наиболее известна из них mamba; еще один референс - это капсулы от Хинтона
интересно, что SSM создавались изначально текстов, а вот CTM и капсулы - для картинок (видео); почему CTM, которые рекуррентны по своей природе, не стали тестировать на текстах - загадка; могу порекомендовать также сайт статьи, очень красивые демки, может быть поэтому на текстах и не показывают, что демки не такие залипательные, но и в статье результатов на текстах нет, что странно
@valuableai
интересно, что SSM создавались изначально текстов, а вот CTM и капсулы - для картинок (видео); почему CTM, которые рекуррентны по своей природе, не стали тестировать на текстах - загадка; могу порекомендовать также сайт статьи, очень красивые демки, может быть поэтому на текстах и не показывают, что демки не такие залипательные, но и в статье результатов на текстах нет, что странно
@valuableai
👍5
Valuable AI / Валентин Малых pinned «решил проэкспериментировать, снял короткое видео с разбором вот этой статьи»
я вам говорил, что LSTM себя еще покажет? собственно, вот: применили к предсказанию ширины годовых колец на деревьях (вторая картинка), а через это и к предсказанию температуры
по предсказанию LSTM со 128 нейронами (нижняя треть первой картинки) нас ждет повторение малого ледникового периода (больше всего известен по второй половине 17 века, когда в Нидерландах замерзали каналы, на что можно посмотреть на картинах того периода), пик похолодания придется на 2063-2073 годы; причем, глобальное потепление нас не спасет, такие дела
P.S. эта статья также пример нормального международного сотрудничества российских и финских ученых, не в пример недавней истории
@valuableai
по предсказанию LSTM со 128 нейронами (нижняя треть первой картинки) нас ждет повторение малого ледникового периода (больше всего известен по второй половине 17 века, когда в Нидерландах замерзали каналы, на что можно посмотреть на картинах того периода), пик похолодания придется на 2063-2073 годы; причем, глобальное потепление нас не спасет, такие дела
P.S. эта статья также пример нормального международного сотрудничества российских и финских ученых, не в пример недавней истории
@valuableai
🔥15
мой коллега нашел уникальные задачи для рассуждений, которые не идут ни в какое сравнение с MATH500 или AIME; комментарий нашедшего:
ждем бенчмарк!
Редкий язык, нетипичный домен и возможно не утёк в трейн
ждем бенчмарк!
👍18😁16🔥4🤯3🆒1
сегодня будет видео не про меня, а про Ивана Бондаренко (я про него упоминал в своем обзорном посте про NLP группы), в свое время они с коллегами сделали "Писца" - ASR для русского языка, а тут Иван рассказывает о маленьких модельках и их применениях (я недавно писал про работу, где модель размером 1B показывает себя лучше модели на 405B)
к слову, коллеги сделали расшифровку выступления именно с помощью своего Писца, на мой взгляд это отличный пример догфудинга
к слову, коллеги сделали расшифровку выступления именно с помощью своего Писца, на мой взгляд это отличный пример догфудинга
Telegram
Сибирские Нейросети: Речевая аналитика и большие языковые модели для бизнеса
❤️🔥Выступление Ивана Бондаренко на DataFusion 2025:
https://broadcast.comdi.com/watch/rc34lydi
Приятного просмотра ❤️
✍️Наш ИИ сделал расшифровку и саммари доклада:
Основные темы доклада:
1. Прогресс и проблемы больших языковых моделей:
- Потрясающий…
https://broadcast.comdi.com/watch/rc34lydi
Приятного просмотра ❤️
✍️Наш ИИ сделал расшифровку и саммари доклада:
Основные темы доклада:
1. Прогресс и проблемы больших языковых моделей:
- Потрясающий…
🔥12👍3❤1
недавно вышла статья, которая для этого нашего AI несет очень много пользы, а именно 5% экономии на вычислениях
я думаю, что все в курсе, что весь ИИ - это по факту перемножение матриц, например, в архитектуре трансформер механизм внимания требует 5 матричных умножений на одну голову, плюс еще одно для полносвязного слоя; другие операции - это суммирование и нормализация, которые асимптотически пренебрежимы
ну так вот, авторы статьи с помощью RL перебрали возможные вариации представления умножения матриц и нашли ускоренный; графически он представлен на первой картинке, а на второй картинке сравнение количества вычислений с оптимальным алгоритмом - рекурсивным алгоритмом Штрассена (аШ); до размера 256 используется т.н. наивное умножение (как и в современных реализациях аШ), т.к. оно эффективнее на малых размерах, а дальше уже новонайденный алгоритм, дающий 5% преимущества перед аШ
P.S. на моей памяти это первая статья, где - судя по имени - наш соотечественник имеет аффилиацию китайского университета
я думаю, что все в курсе, что весь ИИ - это по факту перемножение матриц, например, в архитектуре трансформер механизм внимания требует 5 матричных умножений на одну голову, плюс еще одно для полносвязного слоя; другие операции - это суммирование и нормализация, которые асимптотически пренебрежимы
ну так вот, авторы статьи с помощью RL перебрали возможные вариации представления умножения матриц и нашли ускоренный; графически он представлен на первой картинке, а на второй картинке сравнение количества вычислений с оптимальным алгоритмом - рекурсивным алгоритмом Штрассена (аШ); до размера 256 используется т.н. наивное умножение (как и в современных реализациях аШ), т.к. оно эффективнее на малых размерах, а дальше уже новонайденный алгоритм, дающий 5% преимущества перед аШ
P.S. на моей памяти это первая статья, где - судя по имени - наш соотечественник имеет аффилиацию китайского университета
🔥11
я уже высказывался про ARR, а тут пришло письмо с обновлениями политики ARR:
обращаю внимание на предпоследний пункт (выделен курсивом), теперь решили переходить к репрессиям, т.к. система выстроена настолько неэффективно, то рецензирование - это совершенно невознаграждаемый труд, от которого все пытаются отвертеться; на этом фоне очень выпукло смотрится последний пункт с виртуальным пряником после реального кнута
на мой взгляд, есть очевидное решение проблемы вознаграждения труда рецензента: нужно просто указывать имена рецензентов в дополнение к именам авторов статей прямо в финальном тексте статьи (отдельно от последних, само собой), тогда возникает а) вознаграждение в виде известности - всем приятно быть рецензентом хорошей статьи, но и б) нежелание ассоциировать свое имя с плохими статьями, так что можно ожидать и более объективных рецензий
* All authors must complete a form confirming that their OpenReview profile is complete and that they are willing to serve as a reviewer if asked.
* Any qualified author may be assigned to review. “Qualified” means at least two papers in main ACL events or Findings, and at least one additional paper in the ACL Anthology or a major ML/AI venue. (See detailed list in the policy).
* Review duty exemptions are possible on a case-by-case basis. Authors serving in other roles (e.g., ACs) are not required to review.
* Reviewers or chairs deemed highly irresponsible such as missing deadlines without warning, violating guidelines on LLM use and professional tone, extremely terse reviews, may be barred from committing their work to EMNLP 2025 and (re-)submitting to the next ARR cycle
* Great reviewers and chairs will receive increased recognition at conferences and may win free virtual registration to an *ACL event.
We encourage everyone to read the full policy here: https://aclrollingreview.org/incentives2025
обращаю внимание на предпоследний пункт (выделен курсивом), теперь решили переходить к репрессиям, т.к. система выстроена настолько неэффективно, то рецензирование - это совершенно невознаграждаемый труд, от которого все пытаются отвертеться; на этом фоне очень выпукло смотрится последний пункт с виртуальным пряником после реального кнута
на мой взгляд, есть очевидное решение проблемы вознаграждения труда рецензента: нужно просто указывать имена рецензентов в дополнение к именам авторов статей прямо в финальном тексте статьи (отдельно от последних, само собой), тогда возникает а) вознаграждение в виде известности - всем приятно быть рецензентом хорошей статьи, но и б) нежелание ассоциировать свое имя с плохими статьями, так что можно ожидать и более объективных рецензий
ACL Rolling Review
Changes to reviewer volunteering requirement and incentives in May 2025 cycle (EMNLP 2025)
TLDR:
👍16💯3❤1
китайский стартап Synyi AI открывает в Саудовской Аравии клинику, в которой ставить диагнозы и выписывать рецепты будет ИИ; в Китае, где все еще остро стоит вопрос нехватки врачей сельской местности, разрешено оказывать консультации с помощью ИИ; но тут уже новый уровень - полноценная клиника
к слову, первый в мире робот, у которого есть полноценное гражданство - это София, она тоже из Саудовской Аравии (точнее сделана она в Китае, но гражданство имеет СА)
P.S. ближневосточные страны в каком-то роде соревнуются во внедрении ИИ, не так давно из ОАЭ была новость, что будут использовать LLM для написания законов
к слову, первый в мире робот, у которого есть полноценное гражданство - это София, она тоже из Саудовской Аравии (точнее сделана она в Китае, но гражданство имеет СА)
P.S. ближневосточные страны в каком-то роде соревнуются во внедрении ИИ, не так давно из ОАЭ была новость, что будут использовать LLM для написания законов
👍5👀5❤3
вышла очень интересная статья от коллег из Циньхуа; основная ее идея изложена на первой картинке - можно взять обученную модель, сделать несколько генераций, выбрать наиболее частый ответ на вопрос и считать его правильным; это такой self-supervised learning от мира RL; на бенчмарках получается очень хороший прирост (вторая картинка); но меня смущает, что это только сжимает петлю самопожирания, не будет ли здесь того явления, которое известно как mode collapse в GAN?
💯6👍3
DeepMind выпустил AlphaEvolve: на картинке общая схема работы, а на видео - демонстрация работы, а именно итеративное улучшение кода; общая идея в том, что выбирается задача, делается функция потерь и итеративно обновляется, улучшается код, который ее решает; в частности они смогли найти лучшее решение для перемножения матриц размером (2,4,4), как раз недавно было еще одно улучшение для алгоритма Штрассена; решение от DeepMind чем-то напоминает AI Scientist от Sakana, но статей само (пока?) не пишет; да и в целом идея с улучшение моделей самих себя стала весьма популярной
👍7
сегодня внезапно приглашаю всех, кто не сможет приехать лично в ВК, посмотреть трансляцию оттуда; расписание здесь; в зале Б1 будет сначала NLP (плюс один доклад из AI4SE), потом Reliable ML и Advanced LLM (почти все доклады несмотря на название секции будут про LLM); начало в 12 часов МСК
VK Видео
Data Fest 2025, день 1: офлайн в Москве 24 мая в гостях у VK
Открываем официальную программу ежегодной конференции Data Fest 2025! Первый день стартует в Москве в гостях у VK. На этом стриме вас ждёт онлайн трансляция из главного зала "Кинозал": 1. 12:00 — 14:05, RecSys секция часть 1 ...обеденный перерыв... 2. 15:10…
🔥13
угадайте, сколько из этих книг, рекомендованных бумажной газетой Chicago Sun-Times своим читателям, реально существуют? ответ тут
😁12👍4
вышла интересная работа от коллег из Allen AI с провокационным названием "могут ли рассуждающие модели не думать и оставаться эффективными?" (пример показан на первой картинке)
авторы показывают на экспериментах, что да, могут (вторая и третья картинки); это означает, что а) можно сэкономить на рассуждениях время и вычисления и б) старый-добрый chain-of-thought все еще хорош
авторы показывают на экспериментах, что да, могут (вторая и третья картинки); это означает, что а) можно сэкономить на рассуждениях время и вычисления и б) старый-добрый chain-of-thought все еще хорош
🔥12