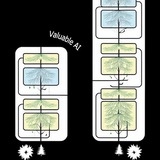
прочитал тут у Сергея Николенко про то, что Sakana AI выпустили вторую версию своего AI scientist; суть в том, что коллеги из Sakana AI автоматически сгенерировали 10 статей, отобрали из них 3 хороших, а потом подали на один из воркшопов ICLR; полученные статьями оценки представлены на картинке, можно предположить, что первая из статей была бы принята
на мой взгляд, эта история история хорошо подсвечивает существующую проблему всей нашей области: аккуратно оформленная работа имеет больше шансов попасть на конференцию, чем неряшливая; и тут многие вероятно подумали: "ну очевидно, аккуратную работу проще понимать, поэтому только такие и должны быть на конференции"
так-то оно так, но проблема заключается в том, что этот критерий совершенно не учитывает научную ценность статьи, т.е. большая часть статей отсекается без, что называется, рассмотрения по существу; на мой взгляд использование LLM уже помогает отчасти снять эту проблему - все статьи становятся оформлены одинаково неплохо
продолжение
окончание
на мой взгляд, эта история история хорошо подсвечивает существующую проблему всей нашей области: аккуратно оформленная работа имеет больше шансов попасть на конференцию, чем неряшливая; и тут многие вероятно подумали: "ну очевидно, аккуратную работу проще понимать, поэтому только такие и должны быть на конференции"
так-то оно так, но проблема заключается в том, что этот критерий совершенно не учитывает научную ценность статьи, т.е. большая часть статей отсекается без, что называется, рассмотрения по существу; на мой взгляд использование LLM уже помогает отчасти снять эту проблему - все статьи становятся оформлены одинаково неплохо
продолжение
окончание
👍11
This media is not supported in your browser
VIEW IN TELEGRAM
начало
Sakana AI идет дальше, чем просто оформление, они не только генерируют текст статьи, а пишут код экспериментов и запускают его, собирают статистику; кажется, ситуация начинает напоминать агентные системы для кодогенерации - только в их случае код пишется по некоему внешнему заданию, а тут - формулируется гипотеза и потом под нее генерируется реализация
мы опять приходим к ранее сформулированной мной дихотомии: реализация против проектирования; если экстраполировать, то простые инкрементальные гипотезы (по терминологии ТРИЗ - изобретения первого уровня) будут достаточно быстро выбираться с помощью подобных инструментов (помимо упомянутого выше Sakana AI Scientist уже есть Google AI co-scientist - на видео), а вот новых идей будет не хватать еще сильнее
окончание
Sakana AI идет дальше, чем просто оформление, они не только генерируют текст статьи, а пишут код экспериментов и запускают его, собирают статистику; кажется, ситуация начинает напоминать агентные системы для кодогенерации - только в их случае код пишется по некоему внешнему заданию, а тут - формулируется гипотеза и потом под нее генерируется реализация
мы опять приходим к ранее сформулированной мной дихотомии: реализация против проектирования; если экстраполировать, то простые инкрементальные гипотезы (по терминологии ТРИЗ - изобретения первого уровня) будут достаточно быстро выбираться с помощью подобных инструментов (помимо упомянутого выше Sakana AI Scientist уже есть Google AI co-scientist - на видео), а вот новых идей будет не хватать еще сильнее
окончание
👍6
начало
продолжение
если присмотреться чуть внимательнее к подходу Sakana, то они вручную отобрали три удачных статьи; можно представить, что работа ученого в нашей (и шире - во всех вычислительных ) области будет сводиться к тому, чтобы отбирать перспективные гипотезы для проверки, оставляя техническую работу машине; я не думаю, что такое будет завтра, как для программирования на днях предсказал CEO Anthropic, но в некоторой перспективе это вполне возможно
P.S. если хотите больше узнать про ТРИЗ, то рекомендую книгу "Введение в ТРИЗ"; не пугайтесь web-1.0 сайта, книга того стоит
P.P.S. пост Сергея
продолжение
если присмотреться чуть внимательнее к подходу Sakana, то они вручную отобрали три удачных статьи; можно представить, что работа ученого в нашей (
P.S. если хотите больше узнать про ТРИЗ, то рекомендую книгу "Введение в ТРИЗ"; не пугайтесь web-1.0 сайта, книга того стоит
P.P.S. пост Сергея
👍7
This media is not supported in your browser
VIEW IN TELEGRAM
пришла новость о том, что Microsoft сделала ИИ-ассистента для помощи геймерам - Copilot for Gaming, который может давать советы во время прохождения игр
иначе, как отрывком из классического мультфильма, я это прокомментировать не могу
иначе, как отрывком из классического мультфильма, я это прокомментировать не могу
😁20🔥2
в пятницу у нас с Сергеем Николенко была бурная дискуссия под моим постом про Sakana AI Scientist, одной из тем там было разделение развития ИИ; если до последнего времени оно было всемирным, то последний год нарастает регионализация, вот и новость в подтверждение моей позиции
👍3😱1
тут вышла новость, в которой говорится, что традиционные сайты теряют посетителей из-за ИИ-агрегаторов, типа ChatGPT и Perplexity; потери доходят до половины посетителей за 3 последних года; на мой взгляд описываемая проблема имеет простое решение - вместо денег за показы рекламы с рекламных платформ, сайты будут брать деньги за показы страниц с ИИ-платформ, как уже делают Associated Press, например
интересно тут другое, одновременно с ковидом появилась книга "Будущее быстрее, чем вы думаете", где авторы предсказывают уход в прошлое рекламы, как таковой из-за того, что ИИ-помощники будут анализировать информацию для пользователей, игнорируя маркетинг; меня это зацепило еще в прошлом году, а теперь появилось наглядное подтверждение
@valuableai
интересно тут другое, одновременно с ковидом появилась книга "Будущее быстрее, чем вы думаете", где авторы предсказывают уход в прошлое рекламы, как таковой из-за того, что ИИ-помощники будут анализировать информацию для пользователей, игнорируя маркетинг; меня это зацепило еще в прошлом году, а теперь появилось наглядное подтверждение
@valuableai
3DNews - Daily Digital Digest
Традиционные сайты массово теряют аудиторию из-за чат-ботов и агентов с ИИ
Специализирующиеся на искусственном интеллекте компании обещали владельцам сайтов, что поисковые системы нового поколения обеспечат им приток посетителей через реферальный трафик. Новый доклад платформы лицензирования контента TollBit показал, что в действительности…
👍10🔥4
пришла новость, что Meta* тестирует свой чип для искусственного интеллекта и готовится начать его широко использовать в 2026 году; месяц назад была аналогичная новость про OpenAI, они хотят представить свой чип уже в этом году; 4 месяца назад была такая же от Amazon
такие чипы принято называть NPU (нейросетевое вычислительное устройство), и их уже сейчас существует несколько; тут надо оговориться, что существуют встроенные в центральный процессор NPU, но я сейчас только о дискретных
первым был Google со своими TPU, которым скоро исполнился 10 лет и которые некоторым даже доступны в colab; на этом список доступных для использования NPU по ту сторону Тихого океана заканчивается
в Китае существует же, как минимум, два - это Ascend от Huawei, на которых уже работает DeepSeek; а также Sophon, которые тоже пишут о поддержке DeepSeek (кстати, название является отсылкой к нашумевшей н/ф книге "Задача трех тел")
* Meta запрещена на территории РФ
такие чипы принято называть NPU (нейросетевое вычислительное устройство), и их уже сейчас существует несколько; тут надо оговориться, что существуют встроенные в центральный процессор NPU, но я сейчас только о дискретных
первым был Google со своими TPU, которым скоро исполнился 10 лет и которые некоторым даже доступны в colab; на этом список доступных для использования NPU по ту сторону Тихого океана заканчивается
в Китае существует же, как минимум, два - это Ascend от Huawei, на которых уже работает DeepSeek; а также Sophon, которые тоже пишут о поддержке DeepSeek (кстати, название является отсылкой к нашумевшей н/ф книге "Задача трех тел")
* Meta запрещена на территории РФ
👍7
Valuable AI / Валентин Малых
пришла новость, что Meta* тестирует свой чип для искусственного интеллекта и готовится начать его широко использовать в 2026 году; месяц назад была аналогичная новость про OpenAI, они хотят представить свой чип уже в этом году; 4 месяца назад была такая же…
для многих будет открытием, что у нас тоже что-то разрабатывают на эту тему: это LinQ от "Хайтэк" (в прошлом IVA Technologies) и NeuroMatrix от НТЦ Модуль; российские чипы в этом году уже должны пойти в серию и быть доступны на рынке (1, 2); конечно, ожидать чудес от наших процессоров не стоит, Huawei тратит миллиарды на создание стабильного ПО и документации своих решений, и не сказать, что имеет широкое внедрение, но продолжим наблюдать
lin-q.ru
Ускорители для искусственного интеллекта LinQ
Дизайн-центр микроэлектроники
👍9👾2😱1
вышла новая работа от Meta* в соавторстве с самим Яном ЛеКуном; концептуально работа очень простая - авторы заменяют сложную в вычислении нормализацию обычным гиперболическим тангенсом (первая картинка), и это не приводит к ухудшению качества; зато приводит к сокращению времени на вычисление этого слоя вдвое, а всей модели Llama на 8% (вторая картинка)
ждем, когда это добавят в NanoGPT, сейчас люди уже тренируют GPT2 меньше, чем за 3 минуты, можно было бы ожидать экономии еще 10 секунд
но интересно другое, в упомянутой работе авторы показывают сохранение качества для большого набора моделей, включая даже диффузии, но преимущество по скорости - только для Llama
так что остается открытым вопрос прироста скорости для других архитектур (не исключая GPT2)
* Meta запрещена на территории РФ
ждем, когда это добавят в NanoGPT, сейчас люди уже тренируют GPT2 меньше, чем за 3 минуты, можно было бы ожидать экономии еще 10 секунд
но интересно другое, в упомянутой работе авторы показывают сохранение качества для большого набора моделей, включая даже диффузии, но преимущество по скорости - только для Llama
так что остается открытым вопрос прироста скорости для других архитектур (не исключая GPT2)
* Meta запрещена на территории РФ
👍8
вышла интересная работа, которая посвящена анализу того, как модели строят рассуждения; конкретно авторы выделяют 4 составляющих - само-проверка, постановка промежуточных целей, поиск обходных путей и поиск решения, начиная с конца рассуждения (посередине на первой картинке); они отмечают, что люди используют ровно те же приемы, когда решают сложные задачи
эта работа поднимает вопрос того, что модели через тексты заимствуют человеческое поведение; это уже пытаются использовать для создания ботов-двойников мировых лидеров; и здесь к месту вспомнить, что моральные установки моделей ломаются от плохого кода
также примерно год назад вышла работа, которая адаптировала подход из психологии к PPO; конкретно, они адаптировали функцию полезности, которую открыл Канеман, анализируя, как люди делают выбор (вторая картинка); к слову, эта функция, а также много другого полезного про то, как работает механизм принятия решений у людей, описана в книге "Думай медленно, решай быстро" (отрывок)
эта работа поднимает вопрос того, что модели через тексты заимствуют человеческое поведение; это уже пытаются использовать для создания ботов-двойников мировых лидеров; и здесь к месту вспомнить, что моральные установки моделей ломаются от плохого кода
также примерно год назад вышла работа, которая адаптировала подход из психологии к PPO; конкретно, они адаптировали функцию полезности, которую открыл Канеман, анализируя, как люди делают выбор (вторая картинка); к слову, эта функция, а также много другого полезного про то, как работает механизм принятия решений у людей, описана в книге "Думай медленно, решай быстро" (отрывок)
🆒4🔥3
на днях я узнал, что исследовательский центр Huawei в Москве переименовали в честь Николая Николаевича Лузина; к своему стыду, я узнал, кто это такой только после этого, но от чего становится еще стыднее - это от того, что он мой прямой предок по математической генеалогии
кто не знает, что это - пример на картинке к посту, вашим предком считается ваш научник; например, моим научным отцом является Владимир Львович Арлазаров
моя генеалогия уверенно отслеживается до Николая Васильевича Бугаева; кстати, не только моя, но и многих современных российских математиков; Николай Васильевич в этом смысле оказался плодовит
глубже него не отслеживается, т.к. докторскую диссертацию он писал самостоятельно, прослушав несколько курсов лекций в европейских университетах, а магистерскую* - непонятно под чьим, я даже предпринял целое расследование, оцифровал его диссертацию, но в ней нет указания на научного руководителя, такие дела
кто не знает, что это - пример на картинке к посту, вашим предком считается ваш научник; например, моим научным отцом является Владимир Львович Арлазаров
моя генеалогия уверенно отслеживается до Николая Васильевича Бугаева; кстати, не только моя, но и многих современных российских математиков; Николай Васильевич в этом смысле оказался плодовит
глубже него не отслеживается, т.к. докторскую диссертацию он писал самостоятельно, прослушав несколько курсов лекций в европейских университетах, а магистерскую* - непонятно под чьим, я даже предпринял целое расследование, оцифровал его диссертацию, но в ней нет указания на научного руководителя, такие дела
👍11😁6🔥2
я что-то упустил год назад момент, когда NAACL переименовались из North American в Nations of Americas (Chapter of ACL); у них там даже своя конституция есть, на минуточку!
🤯3❤1
мне сказали, что можно приглашать всех на мое выступление для ИТМО по поводу нашей статьи Iterative Self-Training for Code Generation via Reinforced Re-Ranking, которую приняли на ECIR 2025
всем, кому интересно про генерацию кода при помощи обучения с подкреплением - добро пожаловать 26 марта в 18:30 (МСК)
нужна регистрация
всем, кому интересно про генерацию кода при помощи обучения с подкреплением - добро пожаловать 26 марта в 18:30 (МСК)
нужна регистрация
Telegram
Valuable AI
⚡️нашу статью Iterative Self-Training for Code Generation via Reinforced Re-Ranking приняли на ECIR 2025! ссылку на статью дам позже, когда выложат на сайт / выложим на arXiv
🔥18❤6
новая модель от Tencent - Hunyuan-T1; из интересного можно отметить то, что это - первая на моей памяти большая модель, сравнимая по качеству с топовыми (на картинке), на гибридной архитектуре трансформер-мамба; если я правильно понимаю, то Tranfromer-Mamba MoE уже была предложена год назад коллегами из AI21 Labs под названием Jamba; интересно, какие отличия у Т1? придется дождаться техрепорта
из интересных фактов, модель обучена на данных до июля 2024 года, похоже, что у них действительно свой претрейн
из интересных фактов, модель обучена на данных до июля 2024 года, похоже, что у них действительно свой претрейн
🔥6
This media is not supported in your browser
VIEW IN TELEGRAM
недавно вышло исследование от Google на тему сходства обработки речи в человеческом мозге и внутри LLM (на видео как раз демонстрация найденного сходства)
в ходе исследования коллеги пришли неожиданному (нет ) выводу:
в ходе исследования коллеги пришли неожиданному (
Unlike the Transformer architecture, which processes hundreds to thousands of words simultaneously, the language areas appear to analyze language serially, word by word, recurrently, and temporally.
🔥6🤯3😁2
сегодня будет 8 лекция моего курса, посвященная LLM; я принципиально делаю курс открытым для всех желающих, так что присоединяйтесь; зарегистрироваться можно здесь
❤17🔥13🥰1
оказалось, что почти 3 года назад коллеги из JetBrains выпустили статью, в которой поставили под сомнение применимость стандартных метрик для оценки качества генерации кода, в частности CodeBLEU
оказалось, что из всех опробованных метрик лучше всего себя ведет (показывает наименьшее расхождение с человеческим суждением) всенародно любимый ChrF (если вы эту аббревиатуру все еще не читаете, как "чешир", то я вас только что заразил), который изначально придуман, как и половина всего в NLP, для машинного перевода; на второй картинке как раз таблица расхождения на датасете Hearthstone
для тех, кто не знает, пример из датасета - на первой картинке; уже по нему можно увидеть основное ограничение - фактически выводы в статье сделаны на очень коротких кусочках кода; я предполагаю, что на более длинных синтаксис будет иметь существенное влияние на оценку
оказалось, что из всех опробованных метрик лучше всего себя ведет (показывает наименьшее расхождение с человеческим суждением) всенародно любимый ChrF (если вы эту аббревиатуру все еще не читаете, как "чешир", то я вас только что заразил), который изначально придуман, как и половина всего в NLP, для машинного перевода; на второй картинке как раз таблица расхождения на датасете Hearthstone
для тех, кто не знает, пример из датасета - на первой картинке; уже по нему можно увидеть основное ограничение - фактически выводы в статье сделаны на очень коротких кусочках кода; я предполагаю, что на более длинных синтаксис будет иметь существенное влияние на оценку
👍3❤1