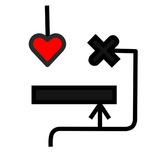
#чтивонаночь
Очень логичная работа от фб - Spirit lm
Давайте возьмем vq токены, будем их смешивать с текстовыми и все поедет. Собственно один из проектов на стажировке в Vikhrmodels ровно про тоже самое, но к сожалению мы запаздали с релизом. А жаль!
Меряют местами непонятно что и непонятно как, бенчей asr и tts нема
Почитать работу meta
Очень логичная работа от фб - Spirit lm
Давайте возьмем vq токены, будем их смешивать с текстовыми и все поедет. Собственно один из проектов на стажировке в Vikhrmodels ровно про тоже самое, но к сожалению мы запаздали с релизом. А жаль!
Меряют местами непонятно что и непонятно как, бенчей asr и tts нема
Почитать работу meta
👍21⚡5❤🔥4🔥1
Forwarded from black_samorez
Love. Death. Transformers.
У вас есть магнитные шарики. Известно что из них можно собрать кубик где будут полосками идти все цвета, полоски имеют одинаковую ширину. Как вы будете собирать из этих шариков кубик так чтобы потратить минимум времени и свести ошибку к минимуму? Сколько…
Два человека, примерно час.
😁63👍7
Forwarded from Mikhail Tikhomirov
Всем привет! Мы в лаборатории анализа информационных ресурсов НИВЦ МГУ проводим исследования по адаптации LLM на русский язык под рабочим названием ruadapt. Год назад я уже писал в этом чате о наших экспериментах с адаптацией LLaMa-2 (Impact of Tokenization on LLaMa Russian Adaptation), теперь же у нас есть новые наработки, которыми я хочу с вами поделиться.
Вот уже год как открытые LLM взяли курс на мультиязычность, однако все мы наблюдаем две старые проблемы: (1) замедление генерации на неанглийских промптах и (2) внезапные китайские иероглифы. А все потому, что словарь модели хоть и стал больше, русских слов в нем почти не прибавилось и как было по 3 русских символа на токен так и осталось (qwen2.5 - 2.5, mistral-nemo - 3.0, llama-3 - 3.0, gemma - 3.2). Как результат мы не только тратим на русские слова раза в 2 больше токенов чем на английские (отсюда и замедление), но также оказываемся неспособны полноценно выделять смыслы этих токенов на фоне других (привет 嗨).
В качестве лекарства в нашей работе Impact of Tokenization on LLaMa Russian Adaptation мы предложили просто заменять словарь токенизации, входные и выходные эмбеддинги на адаптированные под русский язык. Год назад это хорошо сработало и даже смогли превзойти исходное качество LLaMA на Russian Supeglue и side-by-side тестах (со всеми ускорениями и экономией контекста).
Но как и все экспериментальныепрепараты методы наш имел ряд побочных эффектов:
1. Во-первых, из-за полной замены токенизации страдали исходные англоязычные знания модели,
2. Во-вторых, несмотря на то, что на выходе мы получаем более качественную базовую модель с точки зрения русского языка, чтобы получить сравнимую с популярными инструктивными версиями моделей требуется произвести сопоставимые процедуры инстракт-тюнинга, при том, что не все подходы воспроизводимы, так как не всегда открыты инструктивные датасеты (у llama-3 он состоял из 10 миллионов примеров)
Вот мы и решили посмотреть, а можно ли как-то совместить наши ruadapt базовые модели и исходные инструктивные версии (например, модель openchat-3.5 является инструктивной версией модели mistral-7b-v0.1). Мы выяснили следующее:
1. Даже просто заменив матрицы эмбеддингов у инструктивных версий моделей на новые ruadapt версии, модель не перестает работать, хотя и существенно теряет в качестве
2. Если вспомнить линал и посчитать траекторию (проекцию) от весов базы к весам инстракта, то можно откорректировать наши ruadapt эмбедды для лучшей состыковки со слоями инстракта. Этот подход и был нами реализован и назван как Learned Embedding Propagation (LEP).
3. Если этого мало, то после LEP можно произвести дополнительные шаги калибровки и/или инстракт тюнинга, по сути, аналогично любым методам, которые применяются над инстрактами (например, saiga или новый Vikhr)
Таким образом мы создали новое поколение ruadapt моделей: они имеют лучшую токенизацию, по сравнению с исходной моделью и не теряют в качестве, а по ряду бенчмарков даже превосходят качество исходных версий моделей. Первая в списке таких моделей идет RuadaptQwen-3B. Это адаптированная на русский язык модель qwen2.5_3B, к которой была применена описанная процедура. После LEP был произведено несколько этапов инстракт-тюнинга на основе кода проекта saiga. Токенизатор собрали с учетом специализации на русский и сохранения способностей на английском (i.e. 4.0 символа на русский токен), так что ускорение генерации русскоязычного текста до 60%.
На известном бенче Vikhrmodels/arenahardlb наш RuadaptQwen-3B набрал 66 очков , обходя при этом большинство моделей размером в 7-8 миллиардов параметров (и это мы ещё не применили секретную технику "тюна на тесте" 🤡). Это не говорит о том, что модель действительно лучше 7-8 миллиардных моделей, но по крайней мере с точки зрения данной арены не уступает им, имея при этом всего 3 миллиарда параметров.
Welcome попробовать нашу новую модель, будем рады полезному фидбеку, особенно по сравнению данной модели с ее исходным эквивалентом Qwen/Qwen2.5-3B-Instruct :)
https://huggingface.co/RefalMachine/ruadapt_qwen2.5_3B_ext_u48_instruct_v4
Вот уже год как открытые LLM взяли курс на мультиязычность, однако все мы наблюдаем две старые проблемы: (1) замедление генерации на неанглийских промптах и (2) внезапные китайские иероглифы. А все потому, что словарь модели хоть и стал больше, русских слов в нем почти не прибавилось и как было по 3 русских символа на токен так и осталось (qwen2.5 - 2.5, mistral-nemo - 3.0, llama-3 - 3.0, gemma - 3.2). Как результат мы не только тратим на русские слова раза в 2 больше токенов чем на английские (отсюда и замедление), но также оказываемся неспособны полноценно выделять смыслы этих токенов на фоне других (привет 嗨).
В качестве лекарства в нашей работе Impact of Tokenization on LLaMa Russian Adaptation мы предложили просто заменять словарь токенизации, входные и выходные эмбеддинги на адаптированные под русский язык. Год назад это хорошо сработало и даже смогли превзойти исходное качество LLaMA на Russian Supeglue и side-by-side тестах (со всеми ускорениями и экономией контекста).
Но как и все экспериментальные
1. Во-первых, из-за полной замены токенизации страдали исходные англоязычные знания модели,
2. Во-вторых, несмотря на то, что на выходе мы получаем более качественную базовую модель с точки зрения русского языка, чтобы получить сравнимую с популярными инструктивными версиями моделей требуется произвести сопоставимые процедуры инстракт-тюнинга, при том, что не все подходы воспроизводимы, так как не всегда открыты инструктивные датасеты (у llama-3 он состоял из 10 миллионов примеров)
Вот мы и решили посмотреть, а можно ли как-то совместить наши ruadapt базовые модели и исходные инструктивные версии (например, модель openchat-3.5 является инструктивной версией модели mistral-7b-v0.1). Мы выяснили следующее:
1. Даже просто заменив матрицы эмбеддингов у инструктивных версий моделей на новые ruadapt версии, модель не перестает работать, хотя и существенно теряет в качестве
2. Если вспомнить линал и посчитать траекторию (проекцию) от весов базы к весам инстракта, то можно откорректировать наши ruadapt эмбедды для лучшей состыковки со слоями инстракта. Этот подход и был нами реализован и назван как Learned Embedding Propagation (LEP).
3. Если этого мало, то после LEP можно произвести дополнительные шаги калибровки и/или инстракт тюнинга, по сути, аналогично любым методам, которые применяются над инстрактами (например, saiga или новый Vikhr)
Таким образом мы создали новое поколение ruadapt моделей: они имеют лучшую токенизацию, по сравнению с исходной моделью и не теряют в качестве, а по ряду бенчмарков даже превосходят качество исходных версий моделей. Первая в списке таких моделей идет RuadaptQwen-3B. Это адаптированная на русский язык модель qwen2.5_3B, к которой была применена описанная процедура. После LEP был произведено несколько этапов инстракт-тюнинга на основе кода проекта saiga. Токенизатор собрали с учетом специализации на русский и сохранения способностей на английском (i.e. 4.0 символа на русский токен), так что ускорение генерации русскоязычного текста до 60%.
На известном бенче Vikhrmodels/arenahardlb наш RuadaptQwen-3B набрал 66 очков , обходя при этом большинство моделей размером в 7-8 миллиардов параметров (и это мы ещё не применили секретную технику "тюна на тесте" 🤡). Это не говорит о том, что модель действительно лучше 7-8 миллиардных моделей, но по крайней мере с точки зрения данной арены не уступает им, имея при этом всего 3 миллиарда параметров.
Welcome попробовать нашу новую модель, будем рады полезному фидбеку, особенно по сравнению данной модели с ее исходным эквивалентом Qwen/Qwen2.5-3B-Instruct :)
https://huggingface.co/RefalMachine/ruadapt_qwen2.5_3B_ext_u48_instruct_v4
huggingface.co
RefalMachine/ruadapt_qwen2.5_3B_ext_u48_instruct_v4 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
50🔥68👍11🥴5💯5❤🔥1🥱1
Forwarded from whargarbl
This media is not supported in your browser
VIEW IN TELEGRAM
efficientvit
TLDR; на реддит пишут что это исходный код того самого эффективного VAE (жмет в 32 раза), который заюзан в Sana
https://github.com/mit-han-lab/efficientvit
TLDR; на реддит пишут что это исходный код того самого эффективного VAE (жмет в 32 раза), который заюзан в Sana
https://github.com/mit-han-lab/efficientvit
🔥14❤🔥3👍2
Love. Death. Transformers.
#чтивонаночь Очень логичная работа от фб - Spirit lm Давайте возьмем vq токены, будем их смешивать с текстовыми и все поедет. Собственно один из проектов на стажировке в Vikhrmodels ровно про тоже самое, но к сожалению мы запаздали с релизом. А жаль! …
пожалуйста отправьте авторов в гаагу, это военное преступление так хуево код писать
бтв буду в амсте 1.11, пишите если хотите на кофе
бтв буду в амсте 1.11, пишите если хотите на кофе
😁49🥴11😇3🤡2
Love. Death. Transformers.
Вышло демо, по пониманию классно, по эстетике не очень flux справа для сравнения генерил тут
если вы хотите аппелировать к MT возможности без перевода(кто в 24 году гоняет t2i без prompt refiner он же переводчик?) то пожалуйста перестаньте
mt aligment для картиночных моделей - очень сомнительная процедура, проще все делать на английском
mt aligment для картиночных моделей - очень сомнительная процедура, проще все делать на английском
👍15✍1
Love. Death. Transformers.
Стабилити релизули Sd 3.5 large на 8b параметров! model space Из интересного - модель хуже FLUXа, но не дистилированная. Посмотрим насколько хорошо будет учится
отбой, по прежнему с женщинами беда
😁95🍓19🥴14😨6🍌4💔2🔥1💋1
Я 1 год считаю ELO у вас в моделях - и то 1000, то 1020, а иногда и 1058. Вы там сумасшедшие что ли все?
😁55
magnet:?xt=urn:btih:441da1af7a16bcaa4f556964f8028d7113d21cbb&dn=weights&tr=udp://tracker.opentrackr.org:1337/announce
https://www.genmo.ai/
https://www.genmo.ai/
Genmo
Genmo. The best open video generation models.
Genmo trains the world's best open video generation models. Create incredible videos with AI at Genmo
Love. Death. Transformers.
еще одна новость вышла пока я ужинал и болтал
в чем проблема? В том что в 80 это по сути каждый 5 ответ - лажа. 49 - каждый второй
ХЗ чего вы все ноете. Вот возьмем меня. Закончил псифак спббгу, работаю скрам-мастером. Выстраиваю процессы по скраму. Вкатился на изичах. Зарплата сейчас - $8к после налогов. Справедливости ради надо сказать, что у меня еще две сдающихся хаты в центре спб, а сам живу у тян. Оттуда капает + иногда довольно часто коучу скраму разные конторы (очень хорошо кодомартышек скрым дисциплинирует + метрики, поэтому все вкатываются). Недавно вот коучил одну из крупнейших гейдев кантор на снг (но не рашка, оналайн дрочильня на воен тематику) - неделя на контракте, две сотни кодомартых на лекциях - единоразовай гонорар по контракту мне - $40к. Собственно вопрос - что вам мешает поступить так же?
Forwarded from неуютный фкнчик
розыгрыш мерча неуютный фкнчик
1 место: футболка «#freekosov»
2 место: 3 презерватива «cuda стандарт индустрии» + стикерпак
для участия надо нажать ниже и подписаться на паблик
результаты в воскресенье 20.10 в полдень
1 место: футболка «#freekosov»
2 место: 3 презерватива «cuda стандарт индустрии» + стикерпак
для участия надо нажать ниже и подписаться на паблик
результаты в воскресенье 20.10 в полдень
👍58🤡29